
| Cortex Index | Next Article |
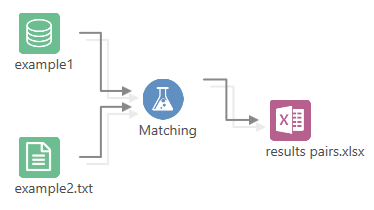
Cortex offers a drag and drop workflow environment for deduplication. It does this through a range of tools that make accessing, cleaning, and outputting data faster and easier. Data preparation tools that include Matching and Normalization functionality. This allows you to find matches in and across any combination of data sources including SQL Server, Excel, & delimited files. Note that if you would like another database connector, please let our support team know and we will introduce additional connectors according to demand.
Requirements
OPERATING SYSTEM
Cortex is compatible with Microsoft Windows 2008/7/10 and Microsoft Windows Server operating systems (2008 or more recent). We strongly recommend using a fully up-to-date and patched operating system, as this will benefit Cortex in terms of robustness, stability, and security.
RAM
Cortex can run entirely in-memory. As the volume of data increases, memory requirements also increase. It is highly recommended that Cortex is used on a machine with enough memory to sufficiently process the data without requiring disk storage.
As a rough guideline:
- a machine with 8 GB of RAM should comfortably process 15 million rows.
- a machine with 16 GB of RAM should comfortably process 30 million rows.
- a machine with 32 GB of RAM should comfortably process 60 million rows.
- a machine with 48 GB of RAM should comfortably process 80 million rows.
If overlapping two sources of data, then use their summed row counts with these guidelines (for example, 100 million vs. 20 million would require 80 GB of RAM.
Note that these figures are highly dependent on factors such as:
- the average size of each row (these figures assume an average row size of 150 bytes);
- which match keys are used (refer to the Configuration Guide for details on match keys);
- the amount of duplication in the data.
Normalization: Note that when an engine is configured for normalization, a row of data added to the engine is discarded immediately after it's processed and output; it is otherwise not retained in RAM. The above RAM requirements are therefore not applicable, and memory usage is minimal.
Disk
Cortex can fall back to storing data on disk, for example if memory usage exceeds a predetermined threshold. This can significantly impact performance, but will allow for processing greater volumes of data. Should disk usage be necessary, then fast disks (such as SSDs) are highly recommended.
Activation
The first time you run Cortex, you will be prompted to enter an activation code - simply enter your code in the activation window (see below) and your install will be activated.
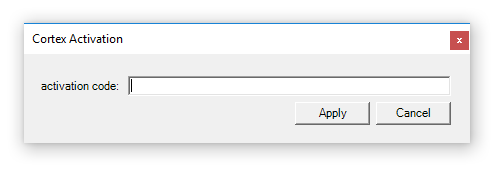
If you need to reactivate or apply a new activation code then when you open Cortex, click on the Activate button up top

Then you simply enter the activation code and hit apply.
In older versions of Cortex, you may need to close and reopen before it reflects the new date.
If you have a Cortex Server license and have multiple users, each user can re-enter the same code.
If you are getting an error when applying a code, please check for whitespace at the beginning or end of the code. If you still have issues then please contact our support department for assistance.
You also have access to newer versions of cortex as part of your ongoing support. For the latest live version please open a ticket with Syniti support at support.syniti.com.
Main Window
Run matchIT Cortex. The main window is divided into 5 main areas.
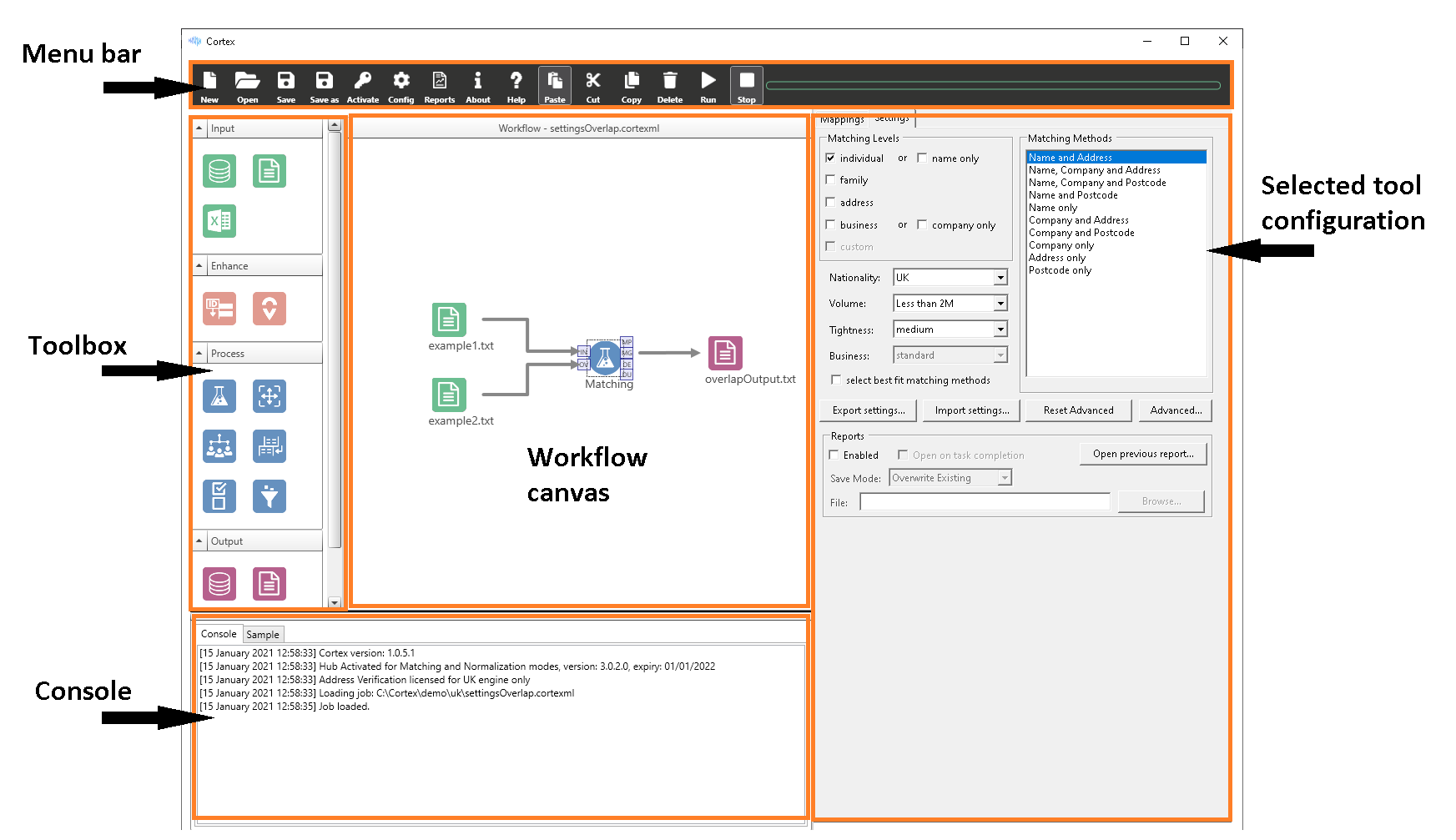
Menu Bar
The menu bar contains various application command buttons and a progress bar.
| Buttons | Description |
|---|---|
 |
Used to clear the workflow canvas, open a previously saved workflow, save the current workflow, and save the current workflow with a different name. |
 |
Used to enter or update an activation code. |
 |
Application settings like, log file and log severity. |
 |
Opens an “About” dialog with version information. |
 |
Used to edit workflow canvas tools and connections. |
 |
Start the current workflow running and abort a running job. |
Cortex Log
Use the Config button to determine whether messages, warnings, errors should be written to a log file and determine the path of that log file.
Console
The console shows messages. Configuration options let you choose which severity of messages to see, from:
- Debug
- Information
- Warning
- Error
- Fatal
Toolbox
The toolbox contains all the tools you can drag onto the workflow canvas divided into the categories: Input, Process, and Output.
Input
The input category has tools to load data from:
- Databases. The following database types are supported:
- Microsoft SQL Server
- Snowflake
- MongoDB
- Salesforce
- If you would like another database connector, please let us know by contacting our support team and we will introduce additional connectors according to demand.
- Delimited files (Tab delimited, comma delimited, etc).
- Spreadsheets.
Enhance
The enhance category has tools for:
- InsertUniqueRef – can be used to insert a unique ref into the data if it doesn’t already contain a unique ID field.
- Address Verification - performs validation against Royal Mail PAF, corrects erroneous/incomplete addresses where possible and appends return codes indicating whether address data is held on PAF or not
Process
The process category has tools for
- Matching – dedupe single table or overlap two tables.
- Normalization – produce normalized version of input data.
- Grouping – group previously matched pairs for multiple runs.
- Union – union two data source with the same layout.
- Select – select a subset of the input columns to pass through to downstream components.
- Sample Groups – filter the Matching groups output to produce a sample of groups for each score.
Output
The output category has tools to output data to:
- Databases. The following database types are supported:
- SQL Server. Refer to Connect to the SQL Server Database as an Output Task.
- Snowflake. Refer to Connect to the Snowflake Database as an Output Task.
- MongoDB. Refer to Connect to the MongoDB Database as an Output Task.
- Delimited files (Tab delimited, comma delimited, etc)
- Spreadsheets
Workflow Canvas
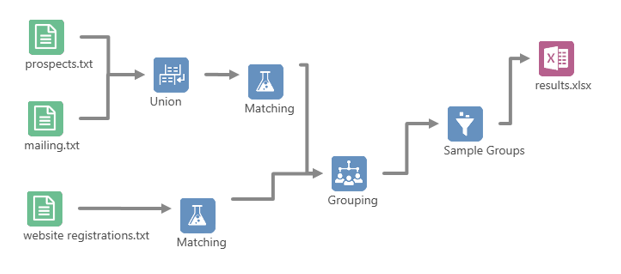
Tools are dragged from the toolbox onto the workflow canvas, where they can be connected together. Once a workflow has been run, if you select a connector and then choose the sample tab (next to console), then you'll be able to see a sample of 100 records that flowed along the connector when the workflow was run.
| Cortex Index | Next Article |