Advanced Configuration
Advanced settings are edited in a popup tabbed dialog.
Matching Tab
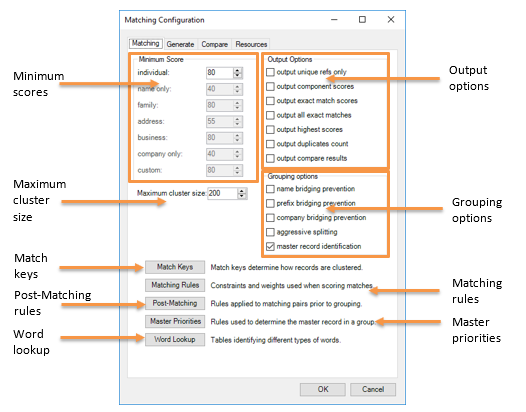
| Minimum scores |
Specifies a matching threshold score for each matching level enabled. |
| Maximum cluster size |
All processed data is added to clusters. When a record is added to an existing cluster, it's then compared to each record already in the cluster, provided the maximum cluster size has not been exceeded. If the cluster has reached the maximum size, then no more comparisons will be performed on that cluster and it will be logged as a large cluster. |
Output Options
| Output unique refs only |
If enabled, then only unique refs are output. If disabled (default), then the output contains a copy of the input data, which can include the unique ref. |
| Output component scores |
If enabled, then scores for mapped components are output for each matching level in addition to total scores. If disabled (the default), then only the total score for each matching level is output. |
| Output exact match scores |
If enabled, then a total score is output for exact matches that is the sum of the sure score setting for all mapped components plus one. Otherwise the score field is blank for exact matches. Regardless of this setting the component scores for exact matches are always blank. |
| Output all exact matches |
When disabled (the default), matching pairs are only output if a record exactly matches the first record of a cluster. If enabled, then all matching pairs are output. |
| Output highest scores |
If enabled, highest scores are also output to the Grouped Matching Pairs and Matching Groups output types. This is the highest score achieved by any matching pair within each group. (Conversely, the base score is the lowest score achieved by the pairs within a group and is always output.) |
| Output duplicates count |
If enabled, the number of duplicates in each group is output to the Matching Groups output type. This is one less than the number of records in the group. |
| Output compare results |
If enabled, the matching matrices indices and acronym match flag are included in the Matching Pairs output type. |
Grouping Options
| Name bridging prevention |
Prevents records with different forenames being grouped together because they all match to a record that is missing forename. |
| Prefix bridging prevention |
Prevents records with ‘Miss’ and ‘Mrs’ being grouped together because they match to a record with ‘Ms’. |
| Company bridging prevention |
Prevents records with different company names being grouped together because they all match to a record with an acronym. (e.g. IBM matches “International Business Machines” and “Injection Blow Moulding”). |
| Aggressive splitting |
If enabled, bridging records will be disassociated from all matching records. If disable (the default), bridging records will remain matched to one sub-group of non-bridging records. |
| Master record identification |
If enabled (default), the master record in each group is chosen according to: Master Priorities rules, then address length, then lowest UniqueRef. If disabled, the master record in each group is simply the record with the lowest UniqueRef. |
Match Keys
Match keys determine how records are clustered. When a new record is added to an existing cluster (containing one or more existing records) the record is compared to each of those existing records. Clusters are used to group potentially matching records.
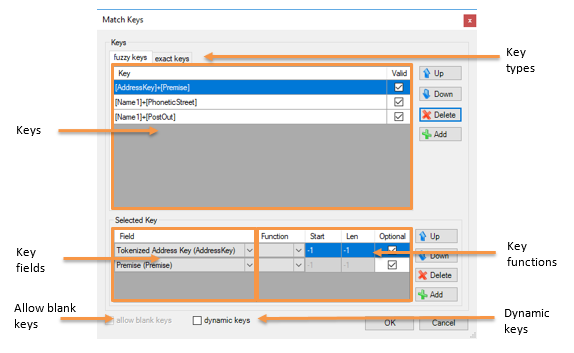
| Keys |
Lists the keys that will be used to cluster records for matching. |
| Key types |
Keys are grouped into ‘exact keys’ and ‘fuzzy keys’. All the records in a fuzzy key cluster are compared to one another. All the records in an exact cluster are automatically considered matching, without needing to compare. |
| Key fields |
Each key is a combination of key fields, e.g. Address Key + Premise. |
| Key functions |
Functions (such as UPPER, TRIM, etc) can be applied to key fields. Functions are best used with raw input data (names, address lines, postcodes, etc.) rather than with the key fields generated by the Hub engine (NameKey, AddressKey, etc.) |
| Allow blank keys |
Key fields can be marked as 'optional' by enclosing them within square brackets, alternatively enabling ‘allow blank keys’ makes all key fields optional. The two methods cannot be used at the same time. |
| Dynamic keys |
In overlap mode (and lookup mode) enabling this option instructs Matching to dynamically choose which keys to use (from those defined), on a record-by-record basis, depending on which input columns are populated. |
Matching Rules
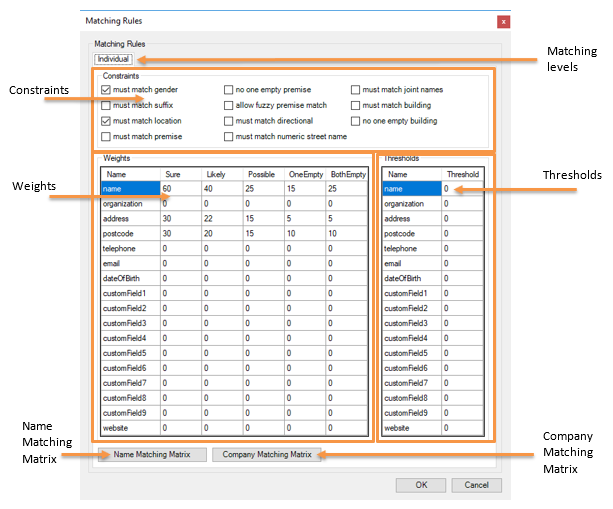
| Matching levels |
The Matching Rules dialog has one tab for each matching level enabled (Individual, Name only, Family, Address, Business, Company only). |
| Weights |
Weights are used when compared records are scored. Weights are configured automatically when the basic configuration settings are specified (nationality, tightness), there is no need to manually configure these weights unless customizations are being made. |
| Thresholds |
Scoring thresholds can be applied to provide further matching requirements when two records are compared. It is not recommended to change these settings. |
Constraints
| Must match gender |
When enabled, potential matches will be disregarded if their genders differ. However, if the gender is unknown in one or both of the records, the records will potentially be classed as a match. |
| Must match suffix |
When enabled, potential matches will be disregarded if their suffixes differ. However, if the suffix is unknown in one or both of the records, the records will potentially be classed as a match. |
| Must match joint names |
When enabled, potential matches will be disregarded if one record has a joint name but the other doesn't. For example, normal behaviour will match "Mr and Mrs J Smith" with "Mr J Smith"; enabling must match joint names will prevent such matches. |
| Address constraints |
The address matching constraints (must match location, premise, directional, etc) are now implemented via post-matching rules, so do not need to be configured here. |
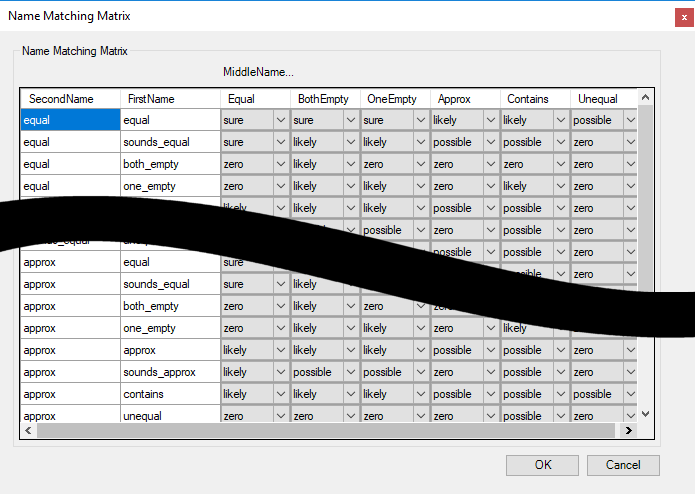
Matching Matrices
Three dimensional matching matrices are used to decide the level of match records should achieve. In the name matching matrix the three dimensions represent the individual name fields: last name, first name, middle name. In the company matching matrix the three dimensions are name1, name2, and name3. The matrix maps the match type for these individual name fields (equal, both_empty, one_empty, sounds_equal, etc.) to an overall match level (sure, likely, possible, etc.).
Post-Matching Rules
Advanced Post-Matching rules are applied to matching pairs prior to grouping. The Advanced Post-Matching rules only apply to fuzzy compared matches. Each rule specifies both a condition using a SQL-like syntax, plus an action that determines what happens when a condition is satisfied.
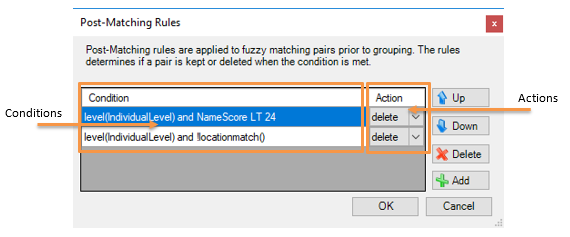
| Conditions |
Rule conditions are logical expressions that results in a Boolean (true or false). An expression can be a function – such as “matches(city)” – or a logical operation such as “AddressScore >= 30”, “City == ‘RALEIGH’”. Conditions can consist of a single logical expression or of multiple expressions (combined using “and”, or “or”). |
| Actions |
Rule actions are either "Keep" or "Delete". If any successful rule specifies a Keep action, then the match is kept. If any successful rule specifies a Delete action, then the match is deleted, but only if the match isn’t being kept. |
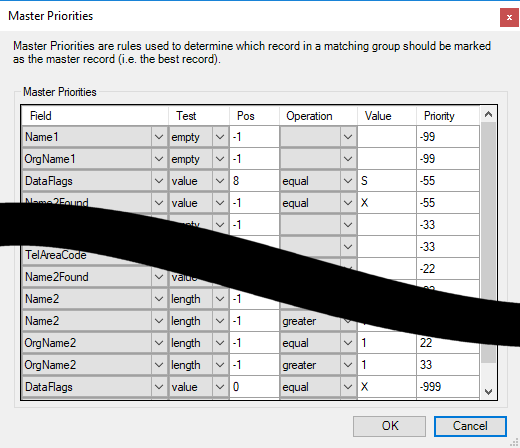
Master Priorities
Master priority rules are used to determine which record in a matching group should be marked as the master record (i.e. the best record).
Word Lookup
The Names and Words tables (NAMES.DAT & NAMES2.DAT) control:
- the matching equivalent of words e.g. Tony = Anthony
- the gender of forenames e.g. John = Male, Susan = Female, Chris = Either
- casing rules e.g. PO Box, IBM, 360Science
- expansion/contraction of abbreviations and correction of typing errors e.g. Svcs = Services, Finacial = Financial
- attributing type to these and other words e.g. Mr = Prefix, Ltd = Business, FL = State, The = Noise.