
Overview
Operational Data Matching offers the ability for process improvements while helping unlock new business value via data quality with higher data integrity. It is available as a module alongside Syniti Knowledge Platform or as a standalone offering as Syniti Match (previously 360Science).
Operational Data Matching can help:
- Find and fix partial data—Identify materials or parts where key information is missing, making it easier to find replacements.
- Standardize inconsistent data—Identify parts or materials that were set up outside of your organization’s standard operating procedures, then match parts and align them with vendors.
- Classify identical data—Detect spelling errors or abbreviated ERP duplicate data.
Using the Parse & Standardize Application
Operational data can be configured and exported using the Parse & Standardize application. The created file can then be imported into Syniti Match Desktop on the Matching and Normalization steps.
Add a Config File
You can add a config file by selecting Add config file from the File selection menu. This step adds a config file to the tree view at the top left of the Parse and Standardize application window.
The tree view shows the list of operational data configuration dictionaries and their contents. The different levels in the tree represent:
- Configuration dictionary file
- Category
- Attributes
NOTE: Description and Extra are reserved fields types and cannot be used as an attribute name. - Pattern
- Values
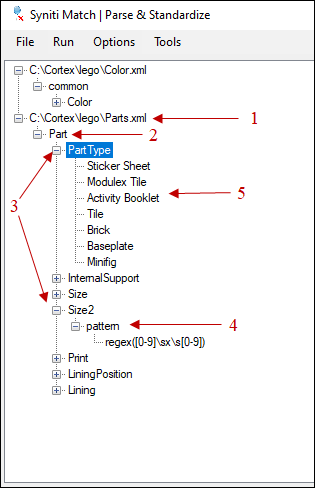
Right-click on any node in the tree to display a context-sensitive menu. This action allows you to add and modify nodes.
NOTE: You will be prompted to save any changes before running or exiting, but you can save at any time by right-clicking on any edited file and selecting Save.
Controls for the selected tree node display to the right of the tree view.
- From the File menu, select Open input file.
- Click Browse… on the InputFile window to select a comma-separated (.csv) or tab-separated (.txt, .tsv) input file. The header record and first data record display in the data grid at the bottom of the window.
- Set the desired size to import in the Sample size field.
-
Click the Mappings tab to map your Input Description field and Unique Reference field.
NOTE: You can also map other input attributes according to your loaded configuration file(s). If a column header has the same name as an attribute, the appropriate value from the Mapping column is automatically selected. If a value does not display in the Mapping column, select the appropriate value from the Mapping list box. The values in the Mapping list box can be adjusted as needed. - Click OK.
Any columns mapped to an operational data mapping (e.g. attribute or description) appear as input columns in the data grid at the bottom of the window. This grid displays the input Description field in the first column and the parsed attributes in the following columns. An Extra column with any unrecognized words from the description also displays here.
The 50 most highly occurring words from the Extra column by occurrence count display in the extra words occurrences grid at the top right of the window.
Saving your Project
To save and load the combination of config files and input files:
- Click on the Project menu.
- Choose Save.
Additional Options
The following actions can be performed after input files have been imported:
- Run—runs normalization with the current saved configuration files. The parsed attribute values are added to the data grid view at the bottom of the window.
- Options > Hide fully parsed—if enabled, hides rows where the Description field has been fully parsed (i.e., the Extra column is empty).
- Options > Show normalized columns—if enabled, shows additional columns for normalized forms of attributes and the values that would be used for each attribute in matching.
- Options > Show output description—if enabled, the output description column in the grid displays at the bottom of the window. This follows the format as specified in the category/description node if present, or attributes in the order specified in the config file if absent.
- Tools > Profile data—profiles the words in the input description field and looks at the format of words to detect things like weights, lengths, prices, etc.
Create a Custom Output Description
By default, the generated output description field consists of the parsed attribute values (for component attributes) in the order listed within your configuration file. However, you can also define a custom description output for each category in your main configuration.
Right-click your category and select Add Description. You can then select a delineating character to separate the attribute values in the output and add text and attribute values to create your desired format. For each attribute, you have the option to add both text before and after, giving you significant flexibility over what can be produced.
Export Settings
Operational data can be configured and exported using the Parse and Standardize application. The created file can then be imported into Syniti Match Desktop on the Matching input step. To export Matching or Normalization data:
- Click on the File menu.
- Select Export.
- If data will be imported into the Matching step, select Match API - Matching Operational data settings. If data will be imported into the Normalization step, select Match API - Normalization Operational data settings.
Import Settings to Syniti Match Desktop
Settings exported from the Configurator can be imported into Syniti Match Desktop. To import these settings into Syniti Match Desktop:
- Select either the Matching or Normalization task.
- Click Operational Data Settings… on the Settings tab.
Operational Data Configuration
View/Edit the Configuration
- Click Advanced… on the Settings tab. The Matching Configuration window displays.
- Navigate to the Operational Data tab.
- Click Edit. The imported file automatically displays in the tree view.
- Edit the configuration here as necessary.
Configure Weights
On the Operational Data tab of the Matching Configuration window, weight used for matching can be configured.
- Click Weights. A weight is defaulted in the Sure column of each attribute.
- Click in the Likely, Possible, OneEmpty, and/or BothEmpty cells in for each attribute
- Assign the appropriate weight. Attributes must match exactly after normalization.
Edit Post-Matching Rules
Post-Matching rules are applied to fuzzy matching pairs prior to grouping. Each rule determines if a pair is kept or deleted when the condition is met. To edit these rules:
- Click Post-Matching on the Matching tab of the Matching Configuration window. By default, one rule for each attribute is automatically set to ensure the attributes match.
- Click Add to add additional rules.
- Enter the appropriate condition.
- Select to keep or delete the attribute from the Action list box once the condition is met.
- Use the Up and Down buttons to prioritize the rules as desired.
- If any attribute is not required to match, delete the associated rule using the Delete button.
Map Operational Data
After importing settings from the Parse & Standardize application (or manually adding operational data configuration dictionaries in Syniti Match Desktop) and attaching an input source to the Matching or Normalization step, the attribute names are available from the Mapping list box in the Input layout grid. Category and Description mappings are also available when configured for operational data. Do not attach the input task to the matching or normalization task until you have imported the operational data settings into the matching/normalization task.