
Fact #4 - Matching Algorithms - the Real Liar Problem - Here is what you need to know
Let’s talk about 'conventiona' matching algorithms. Here’s the data quality industry’s ‘dirty little secret’. Every Data Quality, Data Integration MDM and Data Analytics software company - from IBM to Informatica to Melissa Data, use the same common algorithms to handle the fuzzy matching within their applications.
These conventional matching algorithms fall into two categories – approximate distance algorithms like Jaro–Winkler and Levenshtein used for typos - and phonetic algorithms such as the Soundex and Metaphone used for sound.
|
Algorithm |
Application |
|
Soundex |
Phonetic Algorithm: Use: Sound English names. Encodes based on the 6-phonetic consonant classifications of human speech sounds |
|
Daitch-Mokotoff Soundex |
Phonetic Algorithm: Use: Sound (Variation of Soundex) Slavic (Eastern European) names. |
|
PhonetEx |
Phonetic Algorithm: Use: Sound (Variation of Soundex) Improves on soundex for detection of letter combinations that sound alike, particularly at the start of the word. E.g. PH & F (Phone ~ Fone). |
|
Metaphone |
Phonetic Algorithm: Use: Sound (Variation of Soundex) English names only. Improves on soundex to account some discrepancies between the spelling and pronunciation in English. |
|
Double Metaphone |
Phonetic Algorithm: Use: Sound (Variation of Metaphone) Allows two encoded versions of the string. Attempts to better account for non-English names. (European, Slavic, Germanic, and Asian). |
|
NYSIIS |
Phonetic Algorithm: Use: Sound (Variation of Soundex) Allows minor differences in spelling. |
|
Levenshtein |
Distance Algorithm: Use: Typos. Calculates the smallest number of edit operations (insertions, deletions and substitutions) required to change one string into another. |
|
Damerau-Levenshtein |
Distance Algorithm: Use: Typos Damerau-Levenshtein is a modified version of the Levenshtein algorithm that also considers transpositions as single edits. |
|
Jaro |
Distance Algorithm: Use: Typos Jaro is a measurement of characters in common, being no more than half the length of the longer string in distance, and includes consideration for transpositions. |
|
Jaro - Winkler |
Distance Algorithm: Use: Typos A modified version of the Jaro algorithm distance with logic built on top to add weight for differences near the start of the string more significantly than near the end of the string. Typically used for short strings. |
|
Hamming Distance |
Distance Algorithm: Use: Typos Measures the number of positions at which the corresponding characters between two strings are different, but only used for strings of the same length. |
|
Smith-Waterman |
Distance Algorithm: Use: Typos Similar to edit distance, except that character deletions, are given a different weight. Better adapted for compound names that contain initials only or abbreviated names, and allows gaps. Originally developed measure biological sequences, like DNA. |
We expect a query on structured data like dates or eye color or blood type to return only items that match exactly. But there is obviously no global standard to dictate how a person's contact information is entered into a database.
Fuzzy Matching algorithms essentially change the query from “string A and string B is the same” to “string A and string B are similar”.
Different algorithms have different uses, strengths, and weaknesses. Each algorithm is specifically written and narrowly designed to solve for specific patterns of difference in data, each algorithm generates measures for different data scenarios. and each algorithm serves a different purpose. You’re expected to pick.
It’s important to understand that the decision as to which algorithm is best is not driven by the user - it’s the data that really determines the best algorithm. It’s up to the end user to figure out which algorithm.
The process to determine the best algorithm requires building, testing, analyzing, tweaking and repeating assumptions. When one test fails for an algorithm, pick another and try again until you pick a winner.
It’s also important to recognize that any field of data may require multiple approaches to matching. For example, a distance algorithm would detect the similarity between Smith and Simth, but struggle to detect the similarity between a name like Lindsey and Linzy. Different data defects in any given field of data requires testing of different phonetic and distance algorithms applied to that same field of data.
Other data issues require approaches not addressed by conventional matching algorithms. Such as names like Chuck and Charles or the relationship in city names like New York or NYC and Brooklyn require a completely different approach.
Approximate Distance Algorithms
Approximate string matching algorithms or edit distance algorithms typically assess the difference between two inputs by calculating the number of character additions, deletions, transpositions and replacements required to transform the source string into the target. These algorithms typically include Jaro, Jaro-Winkler, N-Gram, Dice's Coefficient, Jaccard Similarity, Overlap Coefficient, Levenshtein Distance, etc.
These algorithms are designed to report the similarity between two inputs. The Levenshtein distance is the number of characters you have to replace, insert or delete to transform string1 into string2. The algorithm model assumes a given “cost” function which assigns a weight to each edit operation.
For example, Levenshtein: feed the algorithm two strings (x,y), it returns the number of changes you would have to make to obtain an exact match of the x and y strings; e.g. ('Smith', 'Smyth') returns 1.
The algorithm looks like this - but I expect the readers of this to care less about the mathematical formula and more about why their current solution can’t find matches accurately.

While edit distance algorithms are commonplace in many data quality applications and can provide acceptable results for single character transposition keying mistakes, they were not explicitly developed for matching on contact data.
They are more commonly applied to and better suited for ‘long string’ analysis (e.g analyzing DNA, protein, and other bioinformatics-related tasks, plagiarism detection (in music and in text), audio fingerprinting, fingerprint analysis and more).
The reason is highlighted when looking at the data. Instances such as ('Smith', 'Smyth') returns 1 edit, but it gets a lower cost than Hernandez and Fernandez because of the number of changes relative to the length of the string. Additionally, name reversed on entry is common. Strings “Anderson Cooper” and “Cooper, Anderson” are likely to be duplicates, but their edit distance are not even close!
The short strings and single fields typically associated with contact data are not as well suited for distance algorithms as they tend to report high numbers of false matches. As you consider the nuances in customer data such Liz, Elizabeth, Betsey, Leigh, Lee, and Li, and as you will read about address data in the next chapter you will find that the application of distance algorithms in customer data matching becomes more limited.
Seriously - does anyone without a Ph.D. in Applied Mathematics and Computational Science really know the difference between Jaccard Similarity, Dice's Coefficient and Levenshtein - or where to apply them on a given field of contact data?
Soundex is the most commonly referred to phonetic algorithm for indexing names by sound as pronounced in English. It’s been around since 1918 and is today perhaps the most widely used alternative to exact-matching when it comes to contact/names data.
The term “Soundex” is an algorithm, but it’s also often used as a generic term that covers many variations of the algorithm, such as D–M Soundex developed for use on Slavic names, and NYSIIS, Metaphone, Double Metaphone etc. developed as a response to deficiencies in the Soundex.
All variations of Soundex essentially work the same way; they convert each name into a code, or “key”, which can be used to assist in grouping similarly equivalent names. The key is developed using the first letter of the word, followed by several numbers that are assigned based upon stripping the vowels and adding predetermined grouping of the consonants.
Most people who work with data believe Soundex is a reliably accurate phonetic matching algorithm. As you can see from the chart, It’s not. It’s far from it!
 The soundex code for McConaughey is M252. The same code for Matthew McConaughey would also match to Matthew Mackenzie, Magnus, Mocking, and for that matter also Matthew Messemaeckers van de Graaff!
The soundex code for McConaughey is M252. The same code for Matthew McConaughey would also match to Matthew Mackenzie, Magnus, Mocking, and for that matter also Matthew Messemaeckers van de Graaff!
Then consider the results of two studies and ask yourself which concerns you more?
Only 33% of all the matches reported by Soundex were correct, and Soundex would fail to detect 25% of the matches in the database. In other words, a staggering 66% of the matches were incorrect, and 25% were completely missed! And these numbers are not unique to just Soundex.
(Alan Stanier, September 1990, Computers in Genealogy, Vol. 3, No. 7) & (A.J. Lait and B. Randell, 1996)
While Soundex was developed for the purposes of matching names, it doesn’t handle the nuance of names. It’s a phonetic algorithm, and a phonetic algorithm only - it only deals with sound, not pronunciation. It doesn’t understand the pronunciation of words like Milan and Mulan have different stressed syllables, and it certainly doesn’t recognize Chuck from Charles, Elizabeth from Liz or Betty.
Even as an algorithm purpose-built for phonetics, Soundex is far too often incapable of matching names that do sound the same. Names such as such as Dayton and Deighton, Walker and Waker or Thomson and Thompson. Yet names Beard, Brady and Broad - which sound different, all receive the same Soundex key (B630).
Soundex’s Achilles heel is its reliance on the first letter to generate the key. Names like Krane K650 and Crane (C650), or Kadafi (K310), Qadafi (Q310), or Xue (X000) and Hsueh (H200) would be completely missed.
Additionally, Soundex has no tolerance for random typos or misspellings, misfielded names, or double names (e.g. hyphenated married name), and it must be applied on each name element in isolation (first, middle, last). It ignores vowels when the vowel is not the initial letter,
Soundex equates many consonant groups (e.g. C, S and K), but think about the ‘C’ sound. Hard C sound (kuh): cat, cup), soft C sound (suh): cell, city that really makes an ‘S’ sound. The Soundex algorithm does not understand which sound is being used in any name.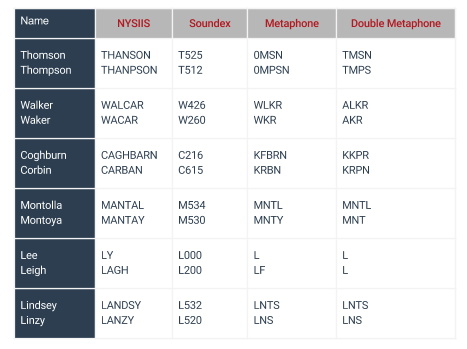
FACT
To be completely accurate - Soundex was not developed for ‘matching’ names. It was developed as a means for indexing names. The Soundex algorithm indexes names based on the six phonetic consonant classifications of human speech sounds ‘articulatory phonetics’. This is where you put your lips and tongue to make consonant sounds. Soundex doesn’t search or match, Soundex indexes/classifies.
Algorithms Speed and Performance
The speed of data matching is an important consideration, and speed is relative to a number of factors.
Fuzzy algorithms are generally applied in the key building process. There are solutions that allow you to apply a fuzzy algorithm in both (early and late stage). In these systems, late-stage application is typically a ‘distance’ algorithm that is applied on the match key (ie. N-Gram, Jaro, etc.).
There are a number of considerations that factor into speed beyond just the algorithms chosen, These considerations include the data, whether the algorithm is applied ‘early’ during key-generation, or ‘late’ during Key-comparison, AND the number of iterative Matchcode combinations selected, AND the ‘order’ of components in conventional matchcodes will all impact the number of records to compare, and processing time. The speed values provided here should be used only as a gauge.
There is a speed penalty every time a record is compared to another record. Algorithms applied on the ‘constructed match keys’ will see a significant negative impact on performance. By applying fuzziness to the matchkey index, the number of comparisons required to process each key value increases significantly!
On high volumes of data - this can have a debilitating impact on performance.
