
In order to effectively match contact data, you need an engine built from the ground up to deal with the variations found in matching name and address inputs. You also need something to effectively match other contact attributes such as email address, phone number, company and date of birth, which pose different challenges. The mAPI is specifically designed to deal with these challenges. By comparing all relevant data and using a variety of strategies to deal with the wide array of hearing, reading, keying and “lack of standards” errors typically found in contact records in most databases, Syniti Data Matching is able to achieve results that are almost human in perception.
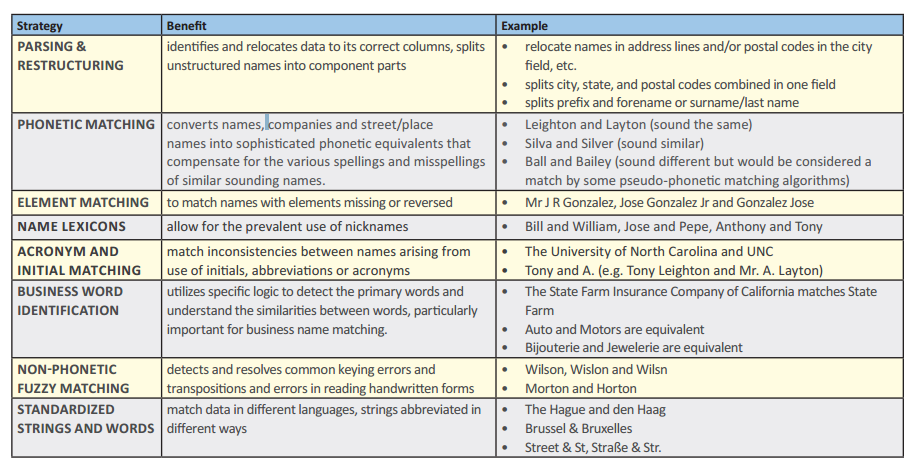
So how would Syniti Data Matching find these matches?
The mAPI encourages use of multiple match keys so that it doesn’t rely on any single item of data always being consistent and present. The keys are tight enough to make sure that the volume of comparisons is reasonable, but loose enough to catch the records with typical errors and inconsistencies. In this example, typical match keys will result in records being compared as follows:
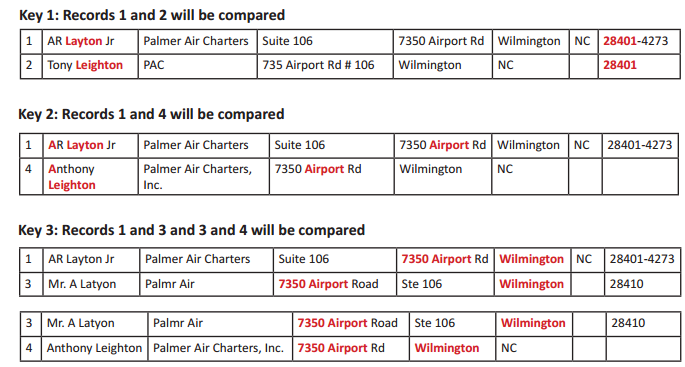
*The data shown in red forms the basis of the match key for that comparison.
Match Keys Used
• Layton & Leighton get same phonetic key
• 5 characters of zip match
• Layton & Leighton get same phonetic key
• Same first initial
• Street name is parsed out & results in a match
• Street number is the same
• Street name and city is parsed out & results in a match
Accuracy meets speed
These match keys run quickly and efficiently on large volumes of data, comparing only records with enough in common to warrant a closer look, not reporting those pairs which don’t reach the specified threshold, and ignoring records which don’t have enough similarity. It’s smart, it’s quick, it scales, and above all, it’s effective