
Typical success metrics for matching usually revolve around the ‘match rate’ - in other words - how many matches (or duplicates) did you find? Lots of matches are good right? Maybe, but don’t be fooled. Look a little deeper and you’ll realize that the true measure of success is identifying TRUE matches while minimizing FALSE matches in a sea of inconsistent, incomplete data.
With various data sources, formats, entry points and collection methods, by the time a contact record is added to the database, it’s often corrupted in numerous ways. This makes matching a far greater challenge. Therefore the true challenge of matching is best illustrated by asking this simple question: You would probably say that these are indeed the same person. But you might be surprised to learn that with most matching engines — this duplication would go completely undetected. Factor in the average rate of duplication in a database of even just a hundred thousand records and the problem is significant.
Are these records the same person?

You would probably say that these are indeed the same person. But you might be surprised to learn that with most matching engines — this duplication would go completely undetected. Factor in the average rate of duplication in a database of even just a hundred thousand records and the problem is significant.
Why Do Common Match Strategies Fail?
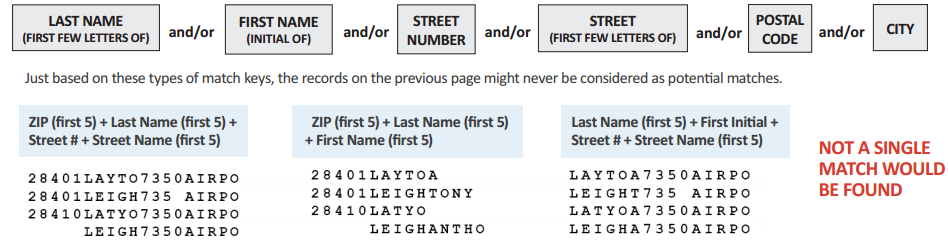
Most matching software identifies duplicate records by using a specific combination of match keys such as:
Why Common Match Strategies FAIL
- They don’t attempt to understand the pronunciation of the name,
- They do not allow for inconsistent, non-standard or transposed data,
- They do not allow for missing or incomplete data, and
- Matches are not graded, so if you want to avoid false matches, you have to review all of the matches found.
If your contact level match key is, say, ZIP (first 5) + Last Name (first 5) + First Name (first 5) you will miss matches where one record is for John Smith and the other for J Smith or where the zip differs. On the other hand, if your match key just includes the initial of first name, you will wrongly match John Smith and James Smith at person level, but still miss matches where one record has a first name of Bill and the other just an initial W for William. Of course, if the name field can’t be parsed into title, first and last names, or the street address parsed into street number and street name, then even these crude match keys won’t be available to you.
While common algorithms (such as Soundex, Jaro-Winkler, Levenshtein, N-Gram and Metaphone) do provide some ability to locate miskeyed variations, these solutions all miss potential matches: for example, where there are phonetic differences, missing data, or where the address can’t be standardized and contains non-standard or misplaced elements. Typically, they also give either black and white answers (match or no match) or very crude percentage match numbers – this means that they either return a high number of false matches or miss a large number of matches, depending on the match keys or threshold you choose.