
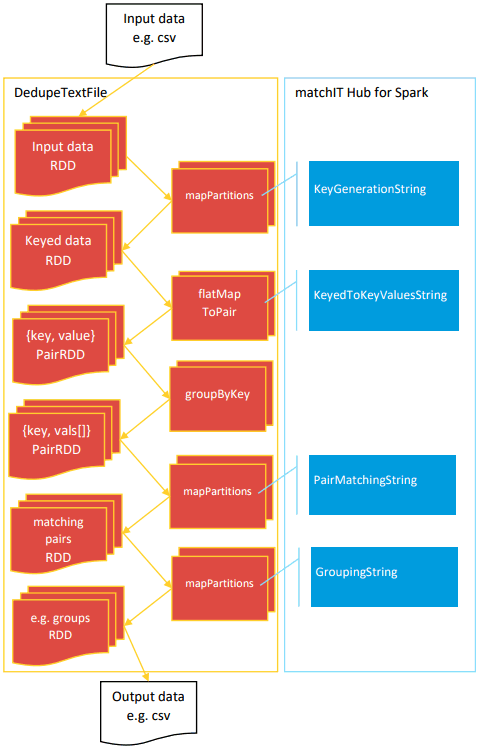
The DedupeTextFile application demonstrates using the matchIT Hub for Spark ‘String’ classes to work with text files, delimited record strings, and Spark RDDs.
Configuration
The command line argument to DedupeTextFile is the name of a configuration file. This is an xml file in the following format:
<?xml version="1.0" encoding="utf-8" ?><config><dedupeTextFile><mainFile>s3://matchithub-spark/samples/DedupeTextFile/example1.txt</mainFile><overlapFile>s3://matchithub-spark/samples/DedupeTextFile/example2.txt</overlapFile><delimiter>\t</delimiter><inputHeader>false</inputHeader><outputPath>s3://matchithub-spark/samples/DedupeTextFile/OutputPairs</outputPath><coalesceOutput>false</coalesceOutput><licenceFile>./activation.txt</licenceFile><logLevel>error</logLevel><groupingAlgorithm>hub</groupingAlgorithm><idField>0</idField><maxIterations>4</maxIterations></dedupeTextFile><hub><data><input table="0" columns="|UniqueRef|FullName|Company|Address1|Address2|City|State|Zip" /><options>...</options></data><matching><outputs>...</outputs></matching><threads>0</threads><advanced><nationality>USA</nationality></advanced></hub></config>
The <dedupeTextFile> section is specific to this application.
| mainFile | The file to deduplicate, or the main file for an overlap. |
| overlapFile | The file to overlap with the main file. Do not specify this to perform an internal dedupe of a single file. |
| delimiter | The delimiter used in the input file and used in the delimited Strings in the RDDs. |
| inputHeader | Indicates that the input file contains a header row, also triggers the use of DataFrames rather than RDDs. |
| outputPath | The output folder for the matching output. |
| coalesceOutput | If true the output is coalesced to a single partition so that only one file is created. |
See DedupeConfiguration for a description of the configuration options: licenceFile, logLevel, groupingAlgorithm, idField, and maxIterations.
The <hub> section configures the underlying matching engine. Refer to the matchIT Hub documentation for details. The <hub> section must contain the following sub-sections: data, matching, threads, advanced.
Running the sample
cd samples/DedupeTextFilechmod 777 DedupeTextFile-jar-with-dependencies.jar run.sh./run.sh