Why did this score 85 on individual
Example 1:
| Record | A |
| Fullname: | Mr. W. R Dayton Jr |
| Company: | The Palmer Air Charters service company |
| Add1: | 7350 Airport Rd #106 |
| Add2: | Wilmington |
| Add3: | NC |
| Zip: |
Example 2:
| Record | B |
| First Name: | Bill |
| Last name: | Deighton |
| Company: | PAC |
| Add1: | Suite 106 |
| Add2: | 7350 Airport Rd |
| Add3: | Wilmington |
| Add4: | NC |
| Zip: | 28401-4273 |
And we’re trying to match them on name or company.
The first question we should be asking is actually if they're even being compared in the first place. Because remember our matching works as a two step process, we line it up on the keys, then score it.
So we have 3 default keys
|
key |
A |
B |
|
mkname1 + mkpostout |
dytym |
dytym + 28401 |
|
mkname1 + mkphoneticstreet |
dytym + ypyt |
dytym + ypyt |
|
mkaddresskey + mkpremise |
wylmypyt + 7350 |
wylmypyt + 7350 |
Because one of the records is missing a zip, we can’t line it up there.
But because we have the same sounding last name and street name, we were able to line it up on the 2nd key.
And because we had the same sounding street/city and same house number, we can line it up on the third key (although because we found it on the 2nd, we’re not going to compare it twice).
So we know its being compared, often clients may wonder why something isn’t scoring, but the actual issue is that it wasn’t being compared in the first place, so that should be the first thing you check.
So now that we know its being compared, let's find out what it's going to score.
By default, the score is a cumulative score, we don’t work on percentages, we try to look at it more like a human would, instead of a machine.
There are three main components to the score
Name
Address
Zip/Postcode
1. Name Scoring
With the Name, we want to look at the mknormalizedname, as mentioned previously, we look at it as last/first/middle.
So we have:
Fullname : Mr. W. R Dayton Jr
Firstname: Bill
Lastname: Deighton
Which normalized to:
DAYTON,W,R
And
DEIGHTON,WILL
There’s a matching matrix xml that we have with many pre determined decisions, so when we look at this from left to right we see this pattern:
The last name sounds equal
The first initial is likely short for Will, which is equivalent to Bill, so we assume that’s equal (we'll scan through the names.dat for those translations).
And one has a middle initial, and one doesn’t
So
Last = Sounds Equal
First = Equal
Middle = One Empty
If we look at the matrix stored by default in
C:\mSQL\config\matchingMatrices\individualLevel\namematchingmatrix.xml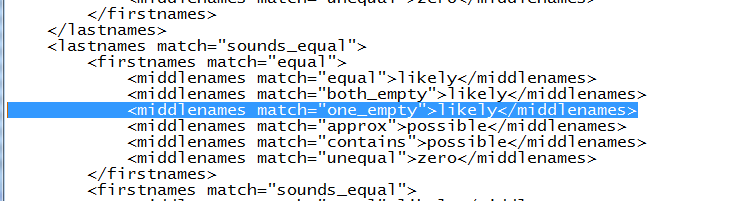
If we navigate through it, we see the pattern it follows, and the associated score. So in this case, the likely score is equal to 40 points.
Whereas if we had a Will Dayton and Bill Dayton, it would be Equal, Equal, both empty, and score sure, which is 60 points
Wheras if the name were transposed like Bill Dayton, and Dayton Will, it would only score possible, which is 25.
Some advanced clients will replace the sure/likely/possible entries in the matrix with decimal values, to get more granularity in their results
2. Address
When we score on the address, we look at the address lines as a whole, we don't explicitly match address1 to address1, address2 to address2, etc...
Record A:
Add1: 7350 Airport Rd #106
Add2: Wilmington
Add3: NC
Record B:
Add1: Suite 106
Add2: 7350 Airport Rd
Add3: Wilmington
Add4: NC
We use our own proprietary algorithm that looks across these columns as a whole.
In this case, even though the number of address lines is different, and the suite’s before the street in one, and abbreviated differently in the other, we’re pretty sure these are dead on, so we will give it a 40 out of 40, whereas say one was missing the city, we’d only get a 34, and if less than 50% of it was right, we’d end up just throwing it out and not scoring at all.
Address scores range from 20-40 by default in the US
Or 15-30 by default in the UK
3. Zipcode
In this case one record had a postcode/zip, and one didn’t,
If you look at the weights under zipcode, you’ll see we still have a score for this situation. (you can access these weights from findmatches or find overlap tasks , each matching level has its own set of weights).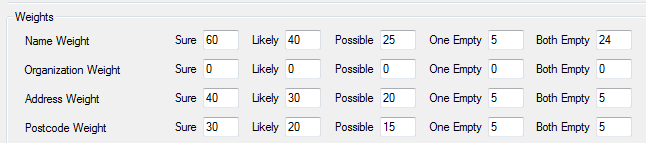
The reason we put a small weight because of the lack of information is that sometimes that score will give it a little extra to push it above the minimum score, as well as separate it from a situation where it was just two completely different postcode/zips.
So if the address wasn’t 100%, we’d need those extra points to push it above the minimum score – which is 80 by default.
Now if both your records actually have a zip, your scores may be different.
Sure:
A sure score is when you have two records with the same 9 digit zip
28401-4273 matching 28401-4273 = sure = 30
Likely:
Now
28401-4273 matching
28401 or
28401-4204
Where only the first five digits are the same = likely = 20
Possible:
Whereas say the zip was transposed
28401-4273 matching
28410
= possible = 15
4. The Cumulative Score
So names are based on the matrix, address is based on an algorithm that looks at the address lines as a whole, and the zip has its own separate rules.
Once we go through all 3 we add up the score
Name = 40
Address = 40
Zip = 5
Total = 85
To get more insight into why your matches scored what they did, ensure you’re breaking out the component scores, its an option in your findmatches/findoverlap task when you’re showing advanced options.