
So you’ve loaded your data into a staging database – in this case we’re using matchIT_SQL_demo database – you start out looking like this. We’re only doing an internal dedupe on the example1 data.
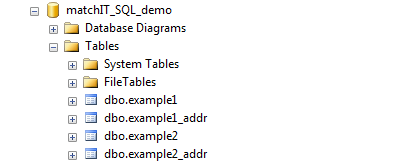
But then you run a package similar to this
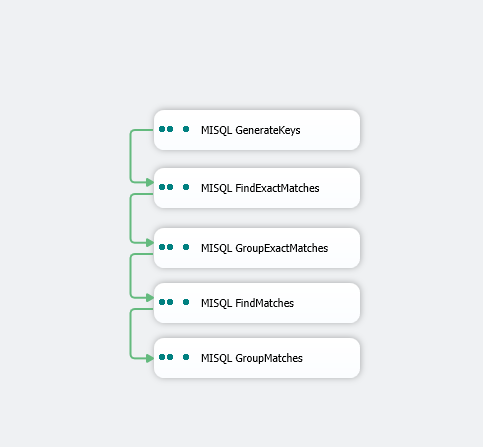
And afterwards – your database looks like this, and you have a bunch of extra tables.
Let's go through each task step by step, and go over what these tables are by the task that produces them.
1. Generate Keys
Generate keys is the first one that’s run, it creates two tables, by default they will use whatever your main table’s name is, but you can rename these tables in the generate keys task, or alter the automatic table suffix’s we use by editing the template xml.
The keys table and output table are pretty straight forward, if you read the API related articles, the basic thing to understand is that the keys are our way of leveling the playing field, and the output table is useful if you want to do things like parse the name.
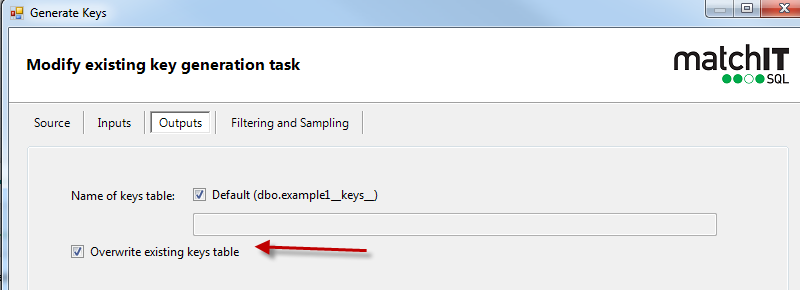
These will get overwritten every time you run a project, although to save on processing time if your table stays the same then you can uncheck the overwrite existing keys for the task where the table is mostly static. Then it will only drop and recreate the keys table if the counts are different between the source and keys table.
2. findexactmatches
This produces a single table, this will get overwritten every time you rerun the package.
If you’re using the default it will be something like
*Tablename*_ exactMatchesRefs
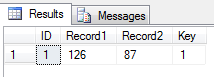
it has 4 columns, the ID, record1, record2, and the key
The ID is just an autonumber just to count the row, record1 and record2 refers to a pair of ID’s from your table, the key refers to key number it was first found on.
Please note the exact overlap will only report 1 to many relationships by default
3. groupexactmatches – this produces two tables
*mainTableName*_exactMatches
*mainTableName*__exact__*guid*
The first table is just where we query all the results and build some groups; this table isn’t meant to be used by the end user.
The second table with the __exact__ in the middle is a working table as well, but this table is significant in that it's telling the next steps which records were already found as matches. We append the GUID to the end of the table name to randomize it, as this table could otherwise be shared when you’re running multiple processes.
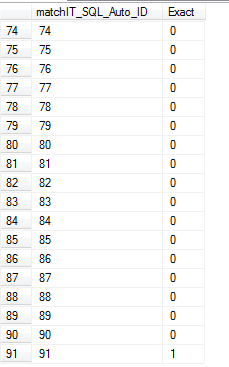
0 = use for fuzzy matching
1 = found as exact match, ignore when doing fuzzy matching
4. findmatches – this produces two tables
A) dbo.example1_fuzzyMatchesRefs
We see it starts out very similar to the exactmatchesrefs with an id and record1 and record2, and a key column at the end.

But unlike the exact matches, which is a simple yes/no match, with the fuzzy matching we grade the score.
We provide you with scores for any matching levels you have chosen, as well as if you’ve chosen to break out component scores those would be displayed here as well.
The other columns are significant when it comes to bridging prevention and master record identification, you can read more in this article.
B) The largeClusters_*GUID* table
This table lists the clusters that contain too many records (i.e. the Maximum Cluster Size has been exceeded). Processing the cluster will therefore be skipped to avoid the stored procedure potentially requiring a significant amount of processing time.
This ideally is empty, if you find matches are being missed and are sure that the keys line up, the first thing you should check is this table, ideally it's going to be empty, but if it isn’t, it might indicate that perhaps you should adjust your match keys or increase the large clusters limit. Based on past support experience, if you need to increase it past 800, then you either should run more exact matching or adjust your keys.
5. groupmatches
Your groupmatches task likely looks something like this:
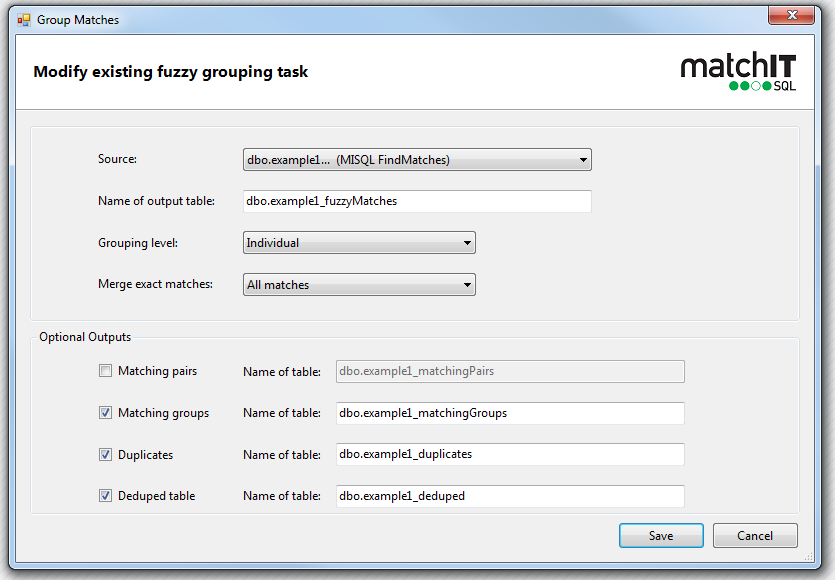
*tablename*_fuzzymatches
You’ll have the default output table – where we combine the exact pairs and the fuzzy pairs for you. If you’re a DBA, you may be fine with just this table, you can write your own queries to interpret it as you will.
Otherwise we use this table to build any optional output tables, and hopefully save you a little bit of SQL work. We normally suggest not using pairs for the internal dedupe, it's often misused for update queries and clients end up with orphan records.
Optional outputs:
*tablename*_matchingPairs - this is side by side of the matches, we normally suggest the matchinggroups table instead for fuzzymatches as the side by side tends to cause confusion and you can't see the whole group together, you may enable the pairs table although when troubleshooting the matching.
*tablename*_matchinggroups - this is the most commonly used table to interpret your matches.
This table has been covered briefly in a previous article, but the main things are
Matchref is a group ID, any records with the same matchref go together.
When the matchref is the same as your ID, then we picked that record as the master of the group, either because we thought it was the most complete based off master record identification, or just because it’s the first one when we sort your ID as a character type column if MRI is off. We currently suggest disabling MRI as a quick performance win if you have a high duplication rate and don't need us to identify the best record.
Any records where the matchref is not equal to your ID, those ID’s are duplicates, and the matchref represents what we think you should merge it with.
You can do your own post processing to reset the matchref to something else, such as based on the most recent transaction or update date.
You can also build a view to bring in the score from the fuzzymatches table as covered previously.
*tablename*_Duplicates - this is a list of all the records from your data source that are duplicates, if all you needed was a list of records that match then here you are, if you’re more advanced in SQL and want to build this on your own, you could just do some select statements off the previous tables and can disable this output to minimize overhead.
*tablename*_Deduped - this is a list of all the records from data source that either are master records, or just unique, if all you needed was a list of unique then here you are, if you’re more advanced in SQL and want to build this on your own, you could just do some select statements off the previous tables and can disable this output to minimize overhead.
6. Other mentions
log table and reports
A) log table - When you’re trying to monitor processes to identify a choke point, or check the status from a remote server, this is great at giving you insight into what’s going on. You can modify the log table name in the template xml if you want separate log tables for separate processes.
B) reports tables – If you find the reports tables annoying, you can turn them off by disabling them in the template, feel free to contact support if you need help with that. If you followed previous recommendations then you don’t have them in the first place.
They provide items such as gender breakdown, data extraction statistics, # of duplicates, breakdown of processing time by key, # of matches etc.
All of this information can also be extracted by running your own queries against the various mSQL results or log tables. you may find it useful to refer to the dataflags fields for information on extraction that happened if you generated an output table back in key generation.