
So if you’ve set up a find matches or find overlap, you’ve seen that the keys were chosen for you depending on your matching level.
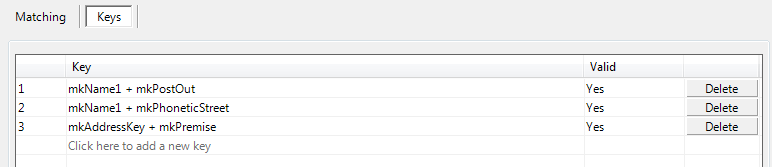
For starters, you can select a key up top, then peruse the drop down below
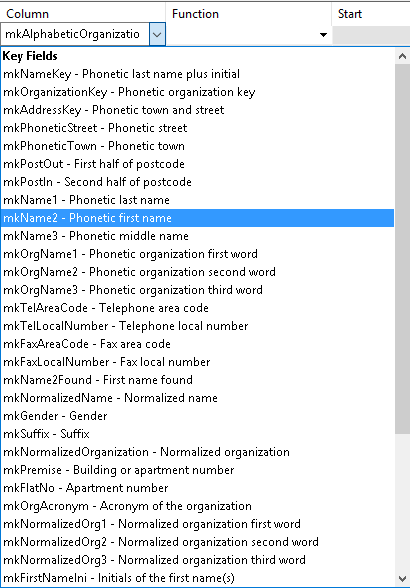

You’ll notice it lists both key fields and input fields
The key fields all start with an mk*, whereas the input fields refer back to whatever you mapped back in generate keys. (town/region/postcode are the same as city/state/zip)
90% of our clients are fine using the default keys, maybe with a minor tweak such as adding a telephone or email to the keys
So why don’t we take a couple records and see what kind of keys they generate.
First we’re going to start with the name related fields
They consist of
mkNormalizedName – Normalized Name
mkName1 – phonetic last name
mkName2 – phonetic first name
mkName3 – phonetic middle name
mkNameKey – phonetic last name plus initial
mksuffix - Suffix
mkGender – Gender
So lets say we have two records that we’re matching
Record A
Fullname : Mr. W. R Dayton Jr
Company: The Palmer Air Charters service company
Add1: 7350 Airport Rd #106
Add2: Wilmington
Add3: NC
Zip:
Record B:
Firstname: Bill
Lastname: Deighton
Company: PAC
Add1: Suite 106
Add2: 7350 Airport Rd
Add3: Wilmington
Add4: NC
Zip: 28401-4273
Besides the fact that they’re inconsistent structures, these are obviously the same person, but its not so easy to line up considering the missing data, that’s what we have the keys for.
Mknormalizedname is the normalized version of the name, so even though its first/last and fullname in another, it will be more consistent here. When we’re matching on name we put the emphasis on the last name, then the first name, then the middle name. we also will convert it to its nickname.
This field is important because when we do the scoring on name, this gives you insight into how the software sees the name.
So Mr W R Dayton becomes
DAYTON,W,R
And
Firstname: Bill
Lastname: Deighton
Becomes
DEIGHTON,WILL,
mkName1 -
This is the phonetic of the last name – we follow the same order as the normalzed name, that’s why name1 is the last name, because its what we are putting the most emphasis on.
Both have the same phonetic of
dytym
we use our own proprietary algorithm to generate these phonetic keys, the main thing to point out here is the y represents a vowel sound
mkName2 –
For Bill we end up with a phonetic first anem of wyl, because we converted Bill to will as part of matching
For the W R, we’re just carrying through the first initial
mkName3 –
This is the phonetic of the middle name, or in this case the middle initial of R in W R Dayton
mkNameKey – phonetic last name plus initial
in this case, the name key is the phonetic of the last name, and the first initial
its dytymW for both records
mksuffix –
if we detect a suffix of some sort, that’s going to go here, commonly Jr, Sr, 2nd, 3rd, etc
mkGender – Gender
This is the inferred gender, we use our names and words lexicon that has a list of common first names and their inferred gender, so we know for sure that Bill is male, and the Mr W R Dayton, the Mr is a common male indicator, so we will return one of four codes
M = Male
F = Female
E = Either (Sam smith – could be short for either Samantha or Samuel)
X = conflicting ( ie: Mr Christina smith )
So that covers the name fields
Now for company related fields,
Lets go through the list
mkNormalizedOrganization
mkOrgname1
mkorgname2
mkorgname3
mkorganizationkey
mkNormalizedOrganization
This field is important because when we do the scoring on name, this gives you insight into how the software sees the name.
Let's say we have two companies
The Palmer Air Charters service company
PAC inc
With the first example, by default we see ‘The’ as a Noise type word, and strip it out, we see ‘service’ and ‘company’ as business type words and strip those out as well. You can manipulate what we ignore or don’t ignore by reviewing the changes suggested in the company only matching video.
With companies we look at them left to right, as opposed to names where its last, first, middle.
So the first example becomes PALMER,AIR,CHARTERS
In the second example, we just recognize inc. as a business word, and strip that out, seeing the PAC in all caps, by default we assume it’s an acronym, so we simply end up with
PAC,, with blanks for the 2nd and third words
mkOrgname1
in this case for the first example, it’s the phonetic of palmer
pymy
for the second example, since we recognized it as an acroym, we just pass through the PAC
mkorgname2
y
in this case the phonetic of Air – which is basically one giant vowel sound
blank for the second example, because we’re ignoring ‘inc.’
mkorgname3
in this case, the phonetic of Charters
Fyty
And just blank for the third example
mkorganizationkey
a concatenation of the first 5 characters of mkorgname1 + first 5 of mkorgname2
This is commonly confused with the normalized organization, if you want your matches to be much tighter, you can use mknormalizedorganization instead or just mkorgname1 + mkorgname2 separately,
Address related fields
mkPremise
mkphoneticstreet
mkphonetictown
mkAddresskey
mkflatno
mkpostout
mkpostin
so lets take these addresses
A)
Add1: Suite 106
Add2: 7350 Airport Road
Add3: Wilmington
Add4: NC
Zip: 28401-4273
B)
Add1: 7350 Airport Rd #106
Add2: Wilmington
Add3: NC
Zip: 28401-4273
mkpremise
The premise in this case is the house number, the house number isn’t always in the same spot, so in this case we identified the 7350 airport road, it doesn’t matter that one address started with the suite, we look at the address lines as a whole
mkPhoneticstreet
similar to the premise number, the street doesn’t need to be in the first address line, in this case we’ve identified Airport Rd as the street, and since words like road/street/circle are generally noise words, we just make a phonetic of Airport
mkphonetictown
We’re generally going to assume the town comes after the street, in this case we’ve identified Wilmington as the town in both situations, we know NC is likely the state.
Mkaddresskey
By default, the phonetic street and town can both be up to 8 characters long, if you want to pare that town and be a bit looser, but still want to use a combination of both, then the address key is a concatenation of both, starting with the town, then the street.
Mkflatno
A flat, or apartment number
Generally, if there’s some kind of numeric, or alpha numeric number that’s following the street
This one key is not very commonly used except in exact keys, more clients prefer changing settings like ‘must match premise’ and ‘no one empty premise’ to keep different apartments in the same building separate.
Mkpostout
In the case of US addresses, the mkpostout is the first five digits of the zip code
So with a zip of 28401-4273 , the 28401 would be in the mkpostout
For a UK Postcode “KT22 8DY”, the mAPI populates mkpostout with “KT22”. Which may also be referred to as the ‘outward part’
Mkpostin
In the case of US addresses, the mkpostout is the last digits of the 9 digit zip code, if just a 5 digit zip the mkpostin would be blank.
So with a zip of 28401-4273 , the 4273 would be in the mkpostin
For a UK Postcode “KT22 8DY”, the mAPI populates mkpostin with “8DY”, or the inward part of the full valid postcode
Optional fields
mkTelAreaCode
mkTelLocalNumber
mkFaxAreaCode
mkFaxLocalNumber
These won’t be available unless you mapped a telephone or fax when you first set up your generatekeys task. You can ensure these fields are populated by checking the advanced settings under generate keys.
In the case of US phone and fax numbers
For 914 – 600-7243
The 914 would be the area code part
The 6007243 would be the local number part
In the case of UK phone numbers
For “01372 225 904” or “01372225904” the mAPI populates this with “01372”.
For “01372 225 904” or “01372225904” the mAPI populates this with “225904”.
New Company Fields added with 2.3.1:
For consistency with the Real Time Processing for SQL Server deployment new keys were added, in the output tab of generatekeys if you click advanced, then you can pick additional key columns to output.
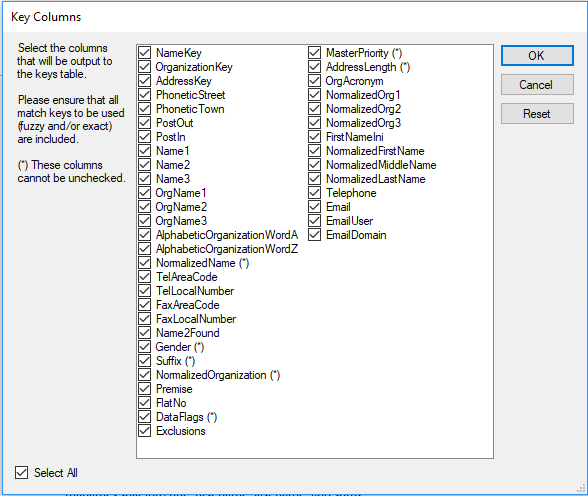
Lets start with company fields - for this exercise we'll still use
The Palmer Air Charters service company
PAC inc
mkNormalizedOrg1
Unlike the phonetic of the company(mkOrgName1) - this is instead the normalized version - think of this as a parsed out version of mkNormalizedOrganization
So for 'The Palmer Air Charters service company' , it will be 'Palmer' - as we're ignoring 'The' as a noise word so 'Palmer is the first significant word
For 'PAC inc' it will be 'PAC' as we recognized that as an acronym
mkNormalizedOrg2
This is the Second significant word from mkNormalizedOrganization
So for 'The Palmer Air Charters service company' , it will be 'Air' - as we're ignoring 'The' as a noise word so 'Air' is the Second significant word
For 'PAC inc' it will be blank as we recognize 'inc' as a noise word
mkNormalizedOrg3
This is the Third significant word from mkNormalizedOrganization
So for 'The Palmer Air Charters service company' , it will be 'Charters' - as we're ignoring 'The' as a noise word so 'Charters' is the Third significant word
For 'PAC inc' it will be blank as there was just the initial acronym
mkOrgAcronym
This is the acronym we've derived off the first 2 or 3 significant words in the company name
For both examples the acronym will be 'PAC' as we carried through the first letters from 'Palmer Air Charters' and recognized PAC as an acronym already in the other record, this may make it easier to line up some outliers when the address isn't as reliable because of vanity names for cities for example throwing off the addresskey.
If the company is a single word, an acronym will not be generated for it as a single letter, if a company has more than 3 significant words, an acronym is only generated off the first three.
mkAlphabeticOrganizationWordA
This is the first alphabetic Organization word- this may allow you to identify transpositions in company names when the order of the words isn't as consistent for some examples.
for our 'The Palmer Air Charters service company' example it actually is Charters, as air wasn't considered significant as it was less than 4 characters, for 'PAC inc' it was blank as the acronym isn't considered when populating this field.
mkAlphabeticOrganizationWordZ
This is the Last alphabetic Organization word- this may allow you to identify transpositions in company names when the order of the words isn't as consistent for some examples.
For our 'The Palmer Air Charters service company' example it actually is Palmer, as Service wasn't considered significant as it was a Noise type word lookup in the names and words, for 'PAC inc' it was blank as the acronym isn't considered when populating this field as it also falls under the 4 character minimum.
New Name Fields added with 2.3.1:
mkFirstNameIni
The initials of the normalized first name
For 'Mr. W. R Dayton Jr' , as well as for
Firstname: Bill
Lastname: Deighton
it would be 'W' , as we normalize Bill to Will then take the initial of the normalized version.
mkNormalizedFirstName
This is the normalized first name
For 'Mr. W. R Dayton Jr' , it would be 'W'
For
Firstname: Bill
Lastname: Deighton
It would be 'Will' , as Bill normalized to Will
mkNormalizedMiddleName
normalized second name, or mid
For 'Mr. W. R Dayton Jr' , it would be 'R'
For
Firstname: Bill
Lastname: Deighton
it would be blank
mkNormalizedLastName
normalized last name
or 'Mr. W. R Dayton Jr' , it would be 'Dayton'
For
Firstname: Bill
Lastname: Deighton
it should be 'Deighton'
In this case those examples don't line up, unlike the mkName1, as its using the last name as is instead of a phonetic version.
New Other Fields added with 2.3.1:
mkEmail
email address with casing standardized
mkEmailUser
user name portion of the email
mkEmailDomain
domain portion of the email