
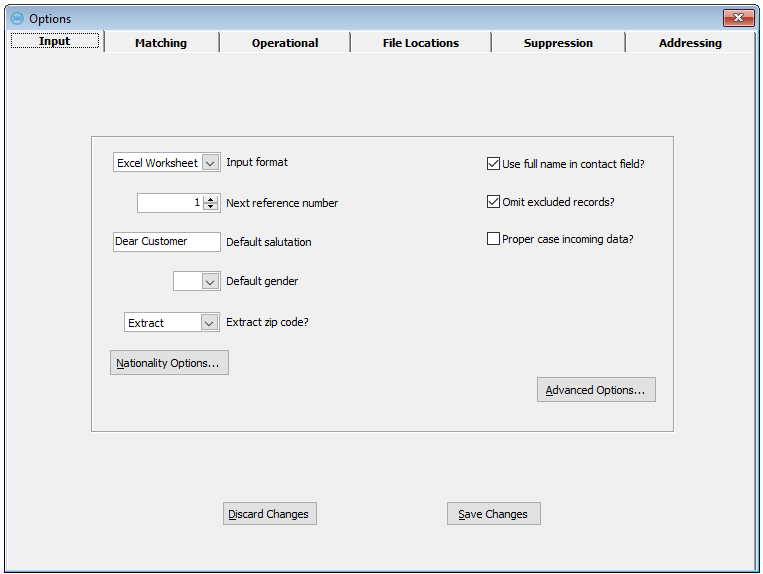
Input Format
Input Format is a drop down list from which you can select as follows:
-
Comma Delimited or COMMA (commonly known as CSV): Use this setting for files that are either Comma or Comma and Quote delimited. This format refers to an ASCII text file in which records can be of variable length, ending with a carriage return and line feed. Commas separate the fields, and additionally double quotation marks can delimit character fields. For example:
- "MR G. SMITH",456620,"123 CHURCH ROAD"
- If the input data does not have the double quotation marks for character fields, this causes a problem if there are commas within a field e.g. Flat 103, 10 High Street intended as one address line. Therefore, this format cannot be guaranteed to be imported 100% successfully.
- Fixed Width or SDF (System Data Format): refers to an ASCII text file in which the fields and records all have fixed lengths, there being no field delimiters, and a carriage return and line feed as the record delimiter. This is a common choice for data coming from IBM and plug-compatible mainframes.
- Tab Delimited or TAB: Tab format is for an ASCII text file in which records can be variable length, ending with a carriage return and line feed. Fields are separated by the TAB character and can be additionally delimited by double quotation marks. This format is preferable to Comma Delimited, as there are unlikely to be problems if the fields are not surrounded by double quotation marks.
- PIPE: Pipe format is identical to tab delimited, except that the fields are delimited by the pipe ("|") character.
-
DBF Table or DBF: Database File format refers to a dBase type file i.e. one conforming to the dBase / FoxPro DBF file standards. mDesktop itself uses this standard for all its tables. If you select this format, you will then be prompted to indicate whether the DBF file containing the data conforms to mDesktop's field naming standards (see "Main File Layout").
- If you reply "No", then you must create a skeleton DBF which does conform to mDesktop's field naming standards, into which mDesktop will copy the data from your DBF. During Import the data from the input DBF file goes first to an intermediate temporary DBF file, to enable mDesktop to transfer it to a file conforming to mDesktop naming standards.
- If you reply "Yes", then mDesktop will change the Input Format from DBF to EXT to tell it just to extract or re-extract Match Keys, salutations etc. without importing the data into the mDesktop Main File. You can use EXT format in a Job Script to extract or re-extract Match Keys in a Main File. If you are importing/extracting through the Import menu, you can use Generate keys to do this without changing the input format.
- Access Table or MDB: Access format; you will be prompted for which of the available tables in the database you want to import.
- Excel Worksheet: Excel v5.0, v6.0 or v7.0 format; note that if there are multiple worksheets, mDesktop will only be able to read the first sheet. Use ODBC for multiple worksheets with the data to be imported being a defined name in Excel.
- Regenerate Keys or EXT: DBF format conforming to mDesktop's field naming standards (see DBF input above).
- DIF: Data Interchange Format used by VisiCalc.
- FW2: Framework II files.
- MOD: Microsoft's Multiplan version 4.01.
- PDOX: Borland's Paradox version 3.5 or 4.0 database files.
- RPD: RapidFile version 1.2.
- SYLK: SYmbolic LinK interchange format used by Microsoft's Multiplan.
- WK1: Lotus 1-2-3 spreadsheet revision 2.x.
- WK3: Lotus 1-2-3 spreadsheet revision 3.x.
- WKS: Lotus 1-2-3 spreadsheet revision 1.A.
- WR1: Lotus Symphony spreadsheet versions 1.1 or 1.2.
- WRK: Lotus Symphony spreadsheet version 1.0.
- XLS: Microsoft Excel version 2.0, 3.0 or 4.0.
- No CRLF: Select this option for an ASCII text file in which records are of fixed length, not ending with a carriage return and line feed, or other specific separator. If you select this format, you will then be prompted to enter the number of characters in each record. During the Import operation, the data goes first to an intermediate flat file with a CRLF terminator for each record. The name of this file is SDFnnn.TXT (where nnn is the length of the record), and mDesktop will delete this file when exiting. If the file contains ASCII null characters instead of spaces, you should reply "Yes" when asked if you want to convert nulls to spaces.
- ODBC: Select this option for a remote data source. You will be prompted for an ODBC Connection file. This file must be created prior to import.
Next Reference Number
The Next Reference Number parameter must be numeric. This will be used for a mDesktop generated unique reference field called UNIQUE_REF. Enter in this field the number at which you wish mDesktop to start sequential allocation of reference numbers, for example, 1. Enter zero if you want a prompt, asking you for a start number, just before Importing commences. If you are Importing two such files prior to merging them, this facility will allow you to make sure the reference numbers in the merged Main File don't overlap.
Default Salutation
This parameter determines the default salutation, either where mDesktop can't determine one (for example, C Smith or Chris Smith, which could be either Mr or Ms), or where the Prefix imported isn't sex-specific (Dr, for example). If you include the word 'Dear' in the default salutation field on the Basic Parameters screen (e.g. actually key in "Dear Customer" and not just "Customer", so the screen shows Dear as a literal followed by "Dear Customer" in the data entry box), then all the salutations derived by mDesktop will start with the word "Dear" unless the salutation for the type of title (or prefix) specifies "Title" only. For example, Mr J Smith will result in a salutation of "Dear Mr Smith" whereas The Bishop of Liverpool will result in a salutation of "My Lord".
Default Gender
The Default Gender parameter is the sex to assume when mDesktop can't determine whether the name is male or female e.g. Chris Smith, C Smith. If you set this parameter to M or F, mDesktop will assume it to be male or female accordingly, and develop a salutation using Mr or Ms as the prefix.
Extract Zip code
When processing address lines, mDesktop can either extract (i.e. move) or copy "floating" ZIP codes from the address lines to a fixed field; set this parameter to "Extract" or "Copy" if required, or else set to "Leave". Note that a field labeled ZIP is required to put the data into – if there is no ZIP field identified during the Setup Wizard, it will automatically add the ZIP field to the main File Layout. If this field is not present, the setting of this parameter is ignored.
Use Full Name in Contact Field
Set this parameter "on" to include the full forename of any incoming name in the CONTACT field; just the initial will be used if the parameter is off. For example, if the parameter is on, and the incoming name is "John Smith", then the generated contact will be "Mr John Smith", if it is off, then the contact will be "Mr J Smith".
Omit Excluded Records
If mDesktop finds Exclusion words such as "Deceased" in any field it is splitting up e.g. addressee, company name or address (if proper casing the address or using a phonetic address key), you can choose to automatically delete them during Import or Generate Keys. If you set this parameter "on", they are deleted, otherwise they are not. All excluded records are marked as such in the FLAG field (if present in the Main File Layout). Thus, if Omit Excluded Records is not switched on, you can choose to delete or mail these records after importing by selecting View Records by Category.
Proper Case Incoming Data
If this parameter is set on, the Import step will convert the address lines in your records (labeled ADDRESS1, ADDRESS2... ADDRESSn) to their proper case. It will also convert ADDRESSEE, JOB_TITLE, DEPARTMENT, and COMPANY to the correct case. mDesktop has a list of words it knows should be either all upper case, or all lower case, or a special mixture; these words can be found in the NAMES table, under the column PROP_CASE. This proper casing will handle punctuation, apostrophes and abbreviations.
mDesktop's default rules for casing data are as follows: letters following an apostrophe are capitalized (e.g. "Mr O'Reilly"), as are letters following "Mc" or (subject to one of the Advanced Input Options) "Mac" at the start of a name (see "Mac Name Treatment"). Double-barreled names have a capital letter after the hyphen. If the name or other word has an entry in the PROP_CASE column in the Names table, it is cased as shown there e.g. BSc, IBM, plc. If not in the Names table, words are all capitals if they contain no vowels, otherwise they are changed to initial capital followed by lower case letters.
To add new words that you would like mDesktop to case differently from the rules above, or to change existing entries in the table, select Names and Words from the Jobs/Setup menu. The Equivalent field contains the word to be looked up, the Name field the matching equivalent (e.g. "Anthony" for "Tony"), and the Type field denotes what sort of word is being added. The Sex field is only used for forenames and prefixes, and the Salutation field is only used for prefixes. The Proper Case field is where any special casing of the word should be entered.
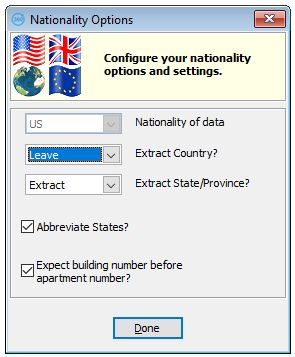
Nationality of Data
As there are other settings (including match key defaults and weights) that need to be set for processing foreign data, you can't change Nationality via this screen: you must use the Save/Restore Setup (see Online help for more details) option under the Setup menu to change the nationality settings.
Extract Country
When processing address lines, mDesktop can either extract (i.e. move) or copy "floating" countries from the address lines to a fixed field; set this parameter to "Extract" or "Copy" if required, or else set to "Leave". Note that a field labeled COUNTRY is required to put the data into – if this parameter is switched on before you use the Setup Wizard, it will automatically add the Country field to the main File Layout. If this field is not present, the setting of this parameter is ignored. Note also that the data in the field will be proper cased if that option is switched on – if you want it in upper case, you must amend the entries for the countries using the Names and Words option under the Jobs/Setup menu.
Extract State/Province
When processing address lines, mDesktop can either extract (i.e. move) or copy "floating" states and provinces from the address lines to a fixed field; set this parameter to "Extract" or "Copy" if required, or else set to "Leave". Note that a field labeled STATE is required to put the data into – if this parameter is switched on before you use the Setup Wizard, it will automatically add the State field to the main File Layout. If this field is not present, the setting of this parameter is ignored. Note also that the data in the field will be proper cased if that option is switched on.
Abbreviate States
Choose this option to have mDesktop abbreviate States or Provinces when processing address lines e.g. to change Pennsylvania to PA.
Expect Building Number Before Apartment Number
This parameter is used when addresses processed by mDesktop contain two numbers in the address line e.g. 12/24 High St. If this parameter is "on", then the first number is taken as a premise number and the second as a flat number, and vice versa if it is off. This is important when matching with the 'Must have premise match?' parameter on, or extracting or copying the premise. As a rule of thumb, set this parameter off if your file contains mainly UK addresses, otherwise turn it on.
Extract Postcode
If the input file contains full UK postcodes which are not in a fixed field, set this parameter to "Extract" to search through the address lines for a postcode and to move it to the postcode field. mDesktop will not extract incomplete postcodes. If the postcodes are in the postcode field, you can select "Leave" to leave postcodes as they are. You can also select "Copy" to copy the postcode from the address lines into a fixed field, but to leave it in the address lines as well
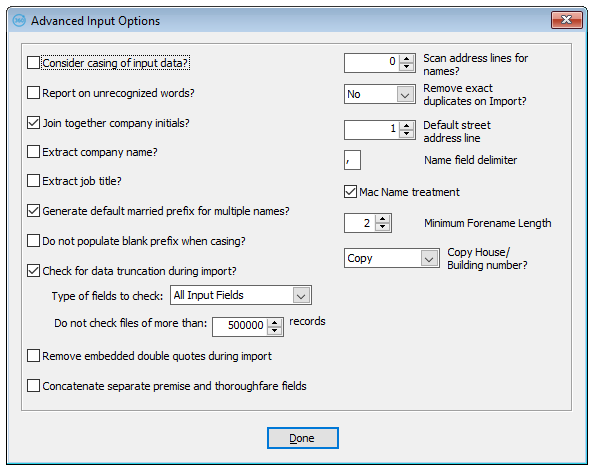
Consider Casing of Input Data
If this parameter is set "on", then mDesktop will consider the casing of the incoming data when it is splitting it up for extracting keys, proper casing, and so forth. This is mainly used for the extraction of name data. For instance, consider the name:
-
"Mr J Smith FRICS",
where "FRICS" is a qualification and "Smith" is the surname. However, if "FRICS" is not in the names table as a qualification, then it will be considered to be a surname, because it is the last substring in the name, and it contains vowels. However, by considering the casing of the name, then it is clear that "FRICS" is not the surname, because it is in a different casing. Basically, all words which are upper or 'specially' cased will be looked at more closely to see if they are qualifications, suffixes, joined initials, and so forth. However, this can lead to problems if the data has been mis-keyed. For instance, consider the name:
-
"Mr John SMith"
It would seem that "SMith" is the surname, but has been entered wrongly, with the intention of entering it in proper case. This sort of situation has the potential to cause problems in the name extraction. As a rule of thumb, if the file you are working with has a lot of names with qualifications, suffixes, or groups of initials joined together, then you should switch this parameter "on", otherwise, switch it "off".
Report Unrecognized Words
This facility is useful when processing foreign files, or files that contain unusual names, qualifications, etc. The parameter that governs this facility is 'Report on unrecognized words?' in the Advanced Input Options. If this is switched on, then mDesktop will record every word processed that it can't find in the NAMES lookup table. These unrecognized words can then be viewed, in order of frequency, and can be added to the NAMES lookup table if appropriate. This is available from the Jobs/Setup menu, and the Unrecognized Words option. The word is shown at the top of the screen, along with how many times it has been found in the table. The word can be added to the NAMES table, or removed from the list of unrecognized words, or just left alone. The type, matching equivalent, sex and salutation type (if appropriate), and proper case for the word can be set for when the word is added to the NAMES table. Note that the table in which the unrecognized words are stored is cumulative, that is, if two files are processed in a row, then the unrecognized words from both files will be recorded. To delete all existing unrecognized words, so that only those from a single file can be viewed, click the 'Delete All' button.
This facility slows the import process down, so only use it if it is genuinely useful for your data
Join Together Company Initials
Set this parameter "on" if you want a group of initials separated by spaces or dots in a company name to be concatenated. For example, if this parameter is "on", then "I B M" and "I.B.M." will be replaced by "IBM". Note that, if the "Proper case incoming data" parameter is set "off", then this parameter will have no effect.
Extract Company Name
Set this parameter "on" to move any business names contained in the ADDRESSEE field to a fixed field labelled COMPANY, if such a field is defined and empty. Business names are recognized by having a word or string defined as a Business word in the NAMES table e.g. Ltd. Take care with this option, as words like "Bank" can be taken to indicate a Business when this isn't the case. It is best either to remove ambiguous words from the Business category of the NAMES table, or to use a subsequent Query to scan and correct records where Addressee (or Address1 or Address2) are blank.
If you want Extract Company Name processing to be applied also to the first one or two lines of the address, you must switch on the Scan Address for Names option.
Note: mDesktop is not able to reliably distinguish between usage in a business name and in a job title or department name so if you switch on both Extract Company Name and Extract Job Title, words or phrases like Computer Services can be of either type and mDesktop is dependent on other words also being in the field (like Manager or Ltd) to work out where to extract it to.
Extract Job Title
Set this parameter "on" to move any job titles contained in the ADDRESSEE to a fixed field labelled JOB_TITLE, if such a field is defined and empty. Job Titles are recognized by having a word or string defined as a Job Title in the NAMES table e.g. Director. mDesktop may treat department names as job titles and extract them from the Addressee field to JOB_TITLE e.g. Customer Services.
Refer also to the description of "Extract Company Name", as the same usage and constraints apply.
Generate Default Married Prefix for Multiple Names
Set this parameter "on" if you want to treat multiple addressees with the same surname as married. For example "Mr. John Smith and Ms. Mary Smith" or "John Smith & Mary Smith" would be changed to "Mr and Mrs Smith".
Scan Address Lines for Names
If, in conjunction with Extract Company Name or Extract Job Title, you set the Scan Address for Names option to 1 or 2, then, during Import, mDesktop will scan not just the ADDRESSEE but also the address lines for a business or personal name. If it is set to 1, only ADDRESS1 will be scanned; if it is set to 2, both ADDRESS1 and ADDRESS2 will be scanned. If mDesktop finds a personal name, it can be used for salutation processing and name matching, and if it finds a business name, it can be used for extracting a company key for matching. This slows down the Import process, so if your ADDRESSEE field always contains an individual name and the company (if any) is always in a specific field which you can label COMPANY, you shouldn't use this feature.
Remove Exact Duplicates on Import
If your file has a lot of exact duplicates in it, you can set this parameter to "Yes" to eliminate them before proceeding to extract Match Keys for the remaining records. This is quicker than using mDesktop's full phonetic key extraction and fuzzy matching logic for these exact duplicates, but uses more disk space and will prove slower if you don't have many of exact duplicates (say 10% or more). If you select "Yes", any exact duplicates are not reported by View Matches etc.
If you do want the records left in the imported DBF for reporting, Q/A etc., you must use Find Matches, Exact Matching.
If you set this parameter to "No", mDesktop will not look for exact duplicates and if you set it to "Ask", it will ask you if you want to delete them after the records are loaded into the DBF during Import.
Default Street Address Line
This parameter is used when mDesktop is generating a phonetic address key, for which it needs to know the thoroughfare and the town in the address. If it cannot locate a thoroughfare in the address, usually because it cannot find a word to indicate one, such as "Street", then mDesktop will assume that the thoroughfare is the contents of the address line indicated by this parameter (if it is greater than zero). For example, if this parameter is set to 1, then mDesktop will take the contents of address line 1 as the thoroughfare if it cannot find one in the address. This parameter should only be used if the addresses in your data are very rigidly structured.
Name Field Delimiter
mDesktop allows for the full name and prefix to be contained in one field, with each component separated by a delimiter. For example, if the delimiter is a comma:
-
O'REILLY,ROBERT,G,MR
The Name Delimiter parameter specifies the delimiter in use. The order is surname, forenames, prefix. The name is split into component parts on Importing. Apart from a comma, any delimiter that isn't alphabetic, numeric, hyphen or apostrophe will suffice. Note however, that inconsistencies in keying (for example, double-barrelled names with hyphen or with space) won't necessarily show up, for example, Johnson-Carr Frederick George Mr will not be matched with Johnson Carr Frederick George Mr.
This parameter also is used to delimit the component parts of the NAME field derived by mDesktop, when not imported as described above.
Mac Name Treatment
Where a surname begins with Mac, when formatting salutations, mDesktop follows this with a small letter or a capital letter, depending on whether the number of letters in the surname is less than the Mac Name Treatment parameter or not. A value of seven will mean that MACKIE will be formatted as Mackie not MacKie, but MACLEAN will be formatted as MacLean. If you want to err on the side of upper casing the next letter, set this parameter to 6, to ensure that the K in MacKay is upper cased, but so would it be in Mackie. If you have the Query module, you can use a Query to search for names beginning with Mac and correct any that are wrongly formatted. You can add exceptions to the rule (e.g. Maccabee, Macclesfield, MacKay, Mackie) to the Names table via the Names and Words option under the Jobs/Setup menu. If you invariably want to use a lower case letter following Mac, set this parameter to 99.
NB: Names beginning Mach are always formatted with a lower case H, e.g. Machin, Machinery. Names beginning Mc are formatted with a capital letter following, if they are greater than 3 characters long.
Minimum Forename Length
This parameter is used to differentiate between forenames and initials. In order to be considered a Forename, the word in question must contain at least this many letters, otherwise it is considered to be Initials.
Copy House/Building Number
This parameter is the same as "Extract Zip code", except that it extracts or copies the premise from the address line, to a field labelled PREMISE. It is not advisable to Extract the premise if you want to output the updated address later, as mDesktop will not know which address line the premise number came from.
Matching Setup
This section is for users who wish to customize mDesktop's matching setup. We recommend that you have some experience with mDesktop before changing the default setup.
Basic Matching Options
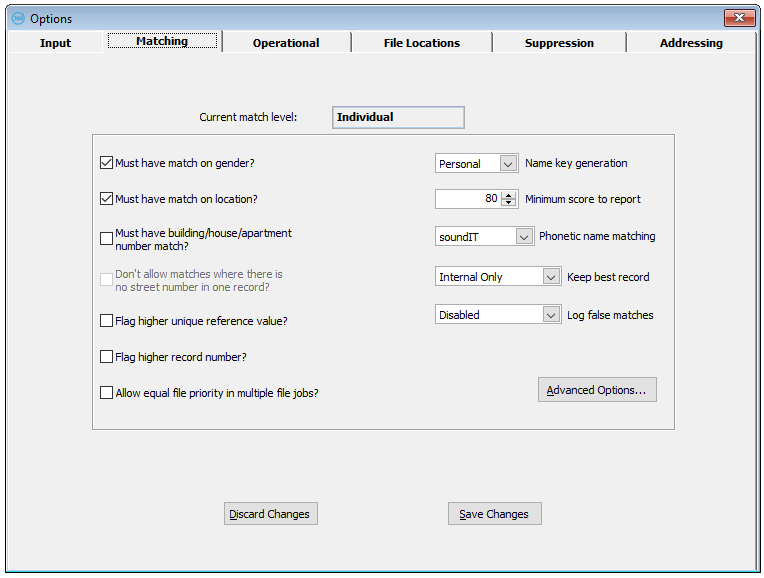
Must have match on gender
If you set this parameter "on", then matches where the sex is different (where the sex is normally deduced from the title) will be suppressed, even if the name matches and there is no independent confirmation of the sex by the forename. Note: even if you have this parameter off, mDesktop will always return a nil score on name (if you are not doing family matching) if the sex of the two records is different and is independently confirmed by the sex deduced from the forename of each record.
Sex is only regarded as different if one record must be Male e.g. Mr and the other Female e.g. Mrs, so it will match Mr and Dr, or Mrs and Dr etc. but not Mr and Mrs.
Must have match on location
If this parameter is set "on", then a matching pair is not reported if a 'location check' has failed. In detail, this means that the zip codes in the two records (if present) must achieve at least a probable match with the address score at least a Possible match, or the address score must be at least a Likely match irrespective of the zip codes, or the zip codes must achieve a Sure match irrespective of the address. This is to prevent false matches where there is some match on address, but where the addresses are clearly not the same, for example "10 High Street, Bookham", and "10 High Street, Alford". Switch this parameter off if you want to match people or companies in different locations; you may want to match on items of data that are independent of location, such as date of birth or bank account. See also the section about Address Matching.
Must have building/house/apartment number match
If you set this parameter "on", then matches with different premise or apartment numbers in the addresses will be suppressed. This could be appropriate if you have a very localized file with a lot of neighboring records, perhaps with similar names.
Don't allow matches where there is no street number in one record
If this parameter is "on", then matches where one of the records has a premise number in the address, and the other hasn't will be suppressed. This is useful when your file has a lot of addresses with house names in the address lines. Note that this parameter has no effect if the "Must have premise match" parameter is off.
Flag higher reference
This specifies the default rule for global flagging of matches, when the deletion priorities are equal or switched off (see Keep best record below). If you set the Flag Higher Reference parameter "on", the record with the higher reference number from each pair is flagged by the Flag Matches option; otherwise the earlier record in the file is flagged.
Name key generation
This parameter governs how the NAME1, NAME2 and NAME3 Match Keys are generated; if the parameter is set to 'Personal', the keys are generated from the personal name, if it is set to 'Business', they are generated from the company name (See the 'Phonetic name matching' parameter below). If you want to switch from any other type of matching to business matching or vice versa, you should do so by using the Save/Restore Setup (see Online help for more information on Save/Restore Setup) option, rather than by just changing this parameter. This is because business matching uses different matching rules to other matching levels.
Minimum score to report
The Minimum Score to Report is the minimum matching score necessary to allow the records to be reported as potential matches. These records are written to the Matches table (or the Merges table for Find Overlap processing).
Phonetic name matching
There are two stages to the matching process that mDesktop uses; the key stage and the scoring stage. The first stage creates standardized and phonetic keys based on the input data, which allows potential matches to be identified. The second stage scores each pair of potential matches, using phonetic and fuzzy matching. This parameter governs the phonetic algorithm that mDesktop uses when generating keys and for scoring.
There are three choices available:
- soundIT
mDesktop provides a unique phonetic algorithm for name matching, called soundIT. soundIT takes account of vowel sounds and syllables in the name, and, more importantly, determines the stressed syllable in the word. This means that "Batten" and "Batton" sound the same according to soundIT, as the different letters fall in the unstressed syllable, whilst "Batton" and "Button" sound different, as it is the stressed syllable which differs. Another advantage of soundIT is that it can recognize groups of vowels and consonants that form vowel sounds – thus it can equate "Shaw" and "Shore", "Wight" and "White", "Naughton" and "Norton", and "Leighton" and "Layton" (which are all reasonably common English surnames).
This algorithm was developed with extensive testing on a large table of the most common surnames in the UK. Therefore, it is specifically designed to be used with English names. If a file with mostly non-English names is processed through matchIT, then you may want to try the 'Loose' soundIT or Soundex algorithms instead. For US data we recommend that you use soundIT, because it is proven to work well also with Spanish, German and other names that occur commonly in the US. soundIT has been designed with foreign language versions in mind (i.e. for data collected in countries where foreign languages are spoken). These could quite easily be developed, according to demand. Please contact your supplier if you are interested in this.
Note that the keys that mDesktop generates are 'Loose' soundIT keys, where all vowel sounds are equated, together with some consonants, such as 'm' and 'n', 'd' and 't', 's' and 'f'. This is so that potential matches are not missed at the key stage; mDesktop uses the 'full' soundIT algorithm at the scoring stage, which will separate out false matches from true matches.
- Loose soundIT
This option is effectively the same as the soundIT option, except that mDesktop uses the 'Loose' soundIT algorithm as described above at the scoring stage. This is for use mainly with non-English names, on which soundIT works less effectively, and can miss true matches. This option should not be used on files with mainly English names, as it can potentially lead to more false matches.
- Soundex
Soundex is a widely-used algorithm (patented just after the First World War!), which constructs a crude non-phonetic key by keeping the initial letter of the name, then removing all vowels, plus the letters H, W and Y, and translating the remaining letters to numbers. It gives the same number to letters that can be confused e.g. 'm' and 'n' both become 5. It also drops repeated consonants and consecutive letters that give the same number e.g. S and C. It only takes the first four characters of the result, or pads it out with zeroes if it is less than four long. Thus all the common spellings and misspellings of the name "Tootill" equate to the same Soundex key: Tootill, Toothill, Tootil, Tootal, Tootle, Tuthill, Totill are all translated to "T340".
The algorithm that mDesktop uses is an enhanced version of Soundex, and is for use mainly with non-English names. This option should not be used on files with mainly English names, as it can lead to false matches e.g. Brady, Beard and Broad get the same Soundex key.
- Non-phonetic
This option constructs a non-phonetic version of the supplied name fields as match keys and allows only non-phonetic name matching.
Note that, at the scoring stage, mDesktop performs name comparisons using data from the NAME field, not from the phonetic keys NAME1, NAME2 and NAME3 – this way it can check for simple typing errors such as "Wilson" and "Wislon" which do not match phonetically.
Keep best record
This parameter governs the use of deletion priorities (see Online help), where mDesktop makes a decision about which is the 'best' record to keep from a matching pair e.g. the one with the most data. There are three settings: Disabled, Internal Only, and Internal and Overlap. Set the parameter to Disabled if you don't want to use deletion priorities, and want to use default rules (see the 'Flag Higher Reference' above). Otherwise set it to Internal Only, where deletion priorities will be used on matches in a single file, or Internal and Overlap, where they are used on matches in a single file and across files.
Use equivalent name
If you set the Use Equivalent Name parameter "on", mDesktop replaces the first name with its equivalent from the NAMES table, if there is an entry for the input forename. This enables, for example, "Tony Smith" and "Anthony Smith" to be picked up as a match. The initial of the original forename is stored in the FLAG field to enable, for example, "Tony Smith" and "T Smith" to still be matched. If time permits, you can Find Matches with this parameter set on, and then re-import the data with the parameter not set on and Find Matches again. The first run would pick up matches for, for example, Tony and Anthony, and the second would pick up any additional matches obscured by keying errors, for example, Tony and Tnoy.
Use equivalent company name
If this parameter is set "on", then the equivalent (according to the Names table) of words indicating a business name, such as "Motors" or "Services" are included in the name keys. This enables, for example, "Wood Green Cars" to match "Wood Green Motors" (because "Cars" has an equivalent of "Motors"), but not to match "Wood Green Carpets". The disadvantage is that words like "Ltd" and "Plc" are also included in the Match Keys so that business names written in different ways, such as "ABC Ltd" and "ABC Plc" may not match. As a rule of thumb, if you are doing business matching on a file that is very geographically concentrated, that is, contains records mostly from the same immediate area, then switch this parameter on, otherwise switch it off.
Use premise range checking
Use premise range checking
To use address coding (the facility to compare a file of addresses with a master file where the thoroughfare records on the master file are split into premise ranges), you must set Use Premise Range Checking ON in the Advanced Matching Parameters.
Do company/job matching when blank names
This parameters governs what mDesktop does when it is matching two personal names which are both empty. If the parameter is "on", mDesktop will compare the company names and job titles (where they exist), and record the match result. The name score result is then recorded as the minimum result of these two comparisons, as long as they both recorded at least a likely match result; otherwise the name result will be simply a 'both empty' result. For instance, if both the names in a potential pair are empty, the company names get a likely match and the job titles get a sure match, then the names will be scored as a likely match.
Must match suffixes
Set this parameter "on" if you want to suppress matches where the suffixes differ, such as "John Smith Sr" and "John Smith Jr", who are probably father and son. Note that, for this to work there must be a populated SUFFIX field in the file; mDesktop will populate this field on import, if it is empty and there is a suffix in the input name.
Compare Part of each Name
If a name isn't equal or approximately equal to its counterpart in the other record, mDesktop looks to see if the full name for the other record "Contains" it, in the sense that Christopher (or indeed Christine) "Contains" Chris. The three Compare Part Name fields specify to mDesktop three values of "n", a number of characters, to see if just the first n characters of each name (surname, first forename, second forename) are contained in the other full name. If you use Phonetic Name Matching, the comparisons mentioned here use the phonetic keys for each name, not the name itself.
To use all of a name or phonetic key in a comparison, set the appropriate one of these parameters to zero; this is the normal setting if you use Phonetic Name Matching. Otherwise specify the number of characters to use. Many diminutives of forenames differ in their endings from the curtailed full version of the name (for example Willy, Andy, Sue), so from this point of view, you should specify agreement of only two or three characters, and certainly no more than four. On the other hand, if you are using the forename look-up table and entering the new forenames that you find, you would normally set the Compare Part 1stname parameter to zero.
Maximum Records to Compare
The Maximum Records to Compare parameter is a whole number specifying the maximum number of records in a set with identical Match Keys, for which mDesktop will compare each record with every other record in the set. If mDesktop finds a key with more records than this value, it reports this information to the screen and to the PERFORM.TXT file in the REPORT sub-directory and skips to the next record with a higher key value.
For example: if you have Maximum Records to Compare set to 50, you are matching on NAME1+REST_PHONE and there are more than 50 records with a blank phone number and NAME1 equal to "dyvys" (e.g. Davies or Davis): mDesktop will compare the first such record with all the others, report that there are (say) 63 records with this key, then carry on with the next record with a higher key.
Combine Addressee and Address
If you set the Combine Addressee and Address parameter "on", mDesktop will combine the ADDRESSEE and ADDRESS1, ADDRESS2 etc. fields when comparing addresses during the matching process. If the Address fields in the Main File often contain an Addressee, it is worth selecting this option.
Accumulate Matching
When you set the Wait for User after Import option off (i.e. no pause) and you set the Accumulate Matching parameter "on", mDesktop will append the references of further matching pairs to the end of the MATCHES table, retaining the existing references; otherwise, it will overwrite these.
When you set the Wait for User after Import option "on" and you set the Accumulate Matching parameter "on", mDesktop will automatically append further matching pairs and won't ask the question "Is this a new matching analysis?"
Flag when grouping unique records
This parameter is used when flagging or grouping matches on a file with a MATCH_REF field. What happens is records that are involved in matches are marked with the unique reference of the 'master' record (the record which is kept) of the matching set; this reference is stored in the MATCH_REF field. This enables matching sets to be easily grouped together by indexing the file on the MATCH_REF field. If this parameter is an empty string, then the unique reference of every record that isn't involved in a matching set is put into its MATCH_REF field; this can make it difficult to distinguish records in matching sets from those that aren't. If this parameter is set to be a non-empty string, say "UNIQUE", then this string is put into the MATCH_REF field of unique records to make it easier to distinguish them from records in matching sets.
Modifying the Weights Used for Matching
Select the Weights option from the Jobs/Setup; Matching Setup menu if you wish to alter the values of the weights attached to the different fields in the matching process. You should not modify the matching weights unless you have read and understood the description in "Introduction to Matching".
A full description of Matching Weights and the Matching Matrices is given in the Online Help.
Deletion Priorities
The Flag Matches option deletes the records with the lowest priorities from each set of matches. If priorities are equal, it keeps the latest record on the file from each set or the one with the lowest Unique Reference, depending on the value of the Flag Higher Reference? Basic Matching option.
A full description of Deletion Priorities is given in the Online Help.
- Field Name is the name of the field in the selected Main File - if any field is not present, the rule for that field is ignored.
- Comment is just for your guidance, to explain if necessary what the field name contains.
- Priority shows the value which is accumulated for each rule that applies to the record being evaluated. When deciding which record to delete, mDesktop accumulates priorities for each record and keeps the record with the highest total priority.
- Value specifies what Value the Field Name must be to obtain the Priority shown. The usual Value is "Empty" e.g. in the first rule above, if the surname (or first business name when matching business names) is empty, a Priority of -99 is given, which downgrades that record heavily. The other common Value is a constant e.g. if you specify rules as follows:
- There are some special Values which only apply to specific field names:
- "Default" applies only to the salutation field: the record will be downgraded in the example above if the salutation is the current default e.g. Dear Customer rather than e.g. Mr Smith.
- "First Name" and "Initial" apply to the first forename field, where it is a full name or an initial rather than empty. "First Name" can also apply to the 2nd significant word in a business name, when matching business names.
- "Derived" applies only to the Prefix field: if the Prefix is derived from the first forename e.g. Ms for Christine, the record will be downgraded compared with a supplied Prefix such as Mrs or Dr.
If you define a field called DEL_PRI (numeric), mDesktop will record the priority of each record that it examines for potential deletion, so you can check that your priorities are working as you expect.

Use One in N import sampling?
Set this option ON to limit the import to an Nth sample of the input file. For example, set this option to 1000 to import only 1 in every 1000 records.
Print Structure?
Set this option ON to automatically display the Main File Layout report before Import. This report lists the different field names in the DBF file that you are importing into, as well as the widths and field types.
Prompt Checklist of Data?
Not available yet. Will be included in a future mDesktop release.
Min, Max, Average Field Widths?
Set this option ON to automatically display the Main File Layout Field Widths report. This report lists everything that the Main File layout report does, but also displays the minimum, maximum and average field lengths within your records.
Show print reminder dialogs?
Set this option ON to prompt for printing reports after preview.
Automatically assign DBF name?
Set this option ON to automatically assign a name for the DBF file at the end of the Setup Wizard, in the same folder as the input file.
Browse After Adding Records?
Set this option ON to automatically view the contents of the Main File that your data has been imported into, before keys are generated.
Wait after Import?
If you tick the "Wait After Import" parameter check box mDesktop will pause after Importing records so you can choose whether or not to proceed to Find Matches and if so which Match Keys to use. If you leave the box blank, mDesktop carries on with matching automatically after Import, using default Match Keys. If the Main File has not been set up for matching, but has been set up for Mailsort, it will carry on automatically with the Do Mailsort processing.
Show Startup Tips?
When you start mDesktop for the first time, you will see a startup tips screen with several options, one of which governs whether or not that screen will be displayed next time. You can set this parameter "On" so that you will see this screen when starting up, or "Off" to disable it.
Sound Effects
If you set the Sound Effects parameter to 'Off', mDesktop will not make any beeps when displaying error messages or when it has finished importing, matching and outputting records. If you set it to 'Quiet', it will make a single beep for all occasions.
Advanced Operational Options

Progress interval
The Progress Interval parameter is an integer. Its value specifies the number of records to process between updates of the progress information on the screen. At the end of each progress interval, updates are written from a temporary buffer to the hard disk for the table being processed. Too low a progress interval slows processing down.
Escape interval
To maximise the speed of the importation and deduplication, mDesktop only checks for any keyboard input from the user (to see if they have pressed escape to abort the process) at a set interval. This parameter is the size of that interval, in seconds.
Default delimited width for Wizard
mDesktop scans a sample of your data and determines the max length for each column, it then factors in a percentage to increase it by, to accommodate for any larger pieces of data that may not have been included in the sample. Some types of field have additional logic and will be set by default to a different width or to a minimum of the (Default Delimited width for Wizard.). With delimited text or Excel files, you should still check your data after import to check for truncation, using the Field Widths Report from the Reports/QA Dashboard.
Default delimited % margin for Wizard
mDesktop scans a sample of your data and determines the max length for each column, it then factors in a percentage to increase it by, to accommodate for any larger pieces of data that may not have been included in the sample. It's very similar to a margin of error when determining how mDesktop generates field widths.
Size of file sample used by Wizard
When importing a file using the Setup Wizard, mDesktop shows you a sample of your file to enable you to identify the contents of each field. This parameter governs the size of this sample, the sample is taken from the beginning of a file.
Max database size to display stats on info screen
mDesktop displays details about the currently selected Main File on the info screen, such as the number of flagged records, and the percentage of records which have postcodes. If the file has a large number of records, however, these details can take a long time to calculate, making it inconvenient when opening files. This parameter sets a record limit above which these details are not automatically calculated when opening a new file. This option cannot be set to lower than 100 records.
Clean up temporary files
This parameter governs what mDesktop does with temporary files when it closes down. If this parameter is set to 'Yes' then mDesktop will always delete temporary files and if it is set to 'No' mDesktop will always leave the temporary files. Alternatively, if this option is set to 'Ask', mDesktop will check with the user before deleting temporary files when closing down. What constitutes a temporary file is defined in the table CLEANUP.DBF in the main mDesktop directory, which contains a list of file masks such as "*.TMP"; you can add other masks to this list. mDesktop will delete all files matching these file masks in the mDesktop directory and all its installed sub-directories.
Log current record number
If you tick this check box, then mDesktop will record the record number (or pair of record numbers and match key for matching) it is currently processing when it is importing a file or doing Find Matches/Overlap. The information is recorded in a text file, which is called IMPORT.LOG for importing, MATCHING.LOG for matching on a single file, and OVERLAP.LOG for a find overlap on two files; all these files are found in the main mDesktop directory. This is useful when there is a problem during one of these operations, as you can inspect this file to see which record (or pair of records) was potentially causing a problem.
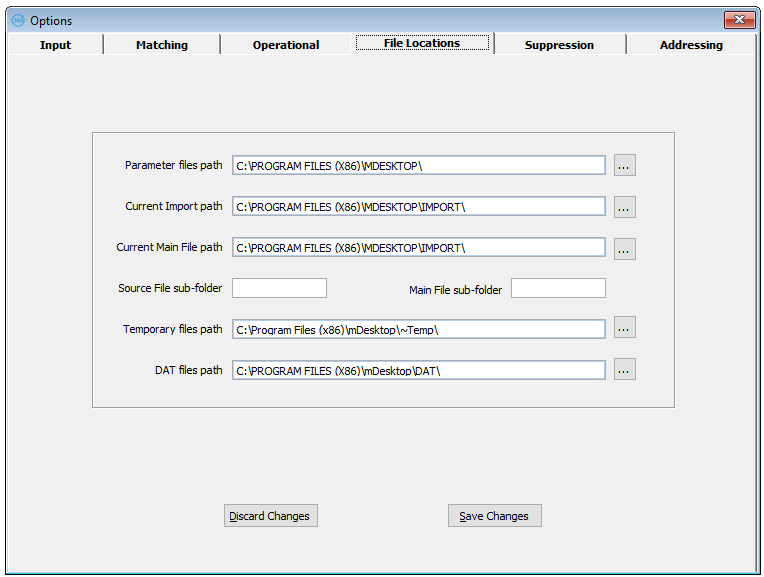
These options allow you to specify where mDesktop should default to when looking for or creating various types of files.
Parameter files path
The Parameter Files Path from the mDesktop Options, File Locations screen allows you to specify a directory for mDesktop to look in for its parameter and matching results databases, instead of the default start directory and its sub directories. For example, if you want to use PARAMS and WEIGHTS for a job for the ABC client which are different from the XYZ client, you can create directories called ABC and XYZ, each with their own, different values. If you then set the Parameter Files Path to ABC, it will use these PARAMS and WEIGHTS, but if there is no PERFORM file in the ABC directory, it will use the one in the Database sub directory of mDesktop.
The files that mDesktop looks for in the Parameter Files Path before its normal default directories, together with the usage and the normal default directory, are listed below. The suffix of each file is DBF unless otherwise specified.
Main directory for mDesktop:
-
PARAMS (the main file containing the parameters from the Other Parameters screen)
-
WEIGHTS (matching Weights)
-
NAMEPARM (the Name Matching matrix)
-
KEYSEQ.DBF and KEYSEQ.CDX (keyboard macros)
-
QUERY.DBF and QUERY.CDX (standard queries)
Database sub directory:
-
PERFORM.DBF and PERFORM.CDX (results of import and matching runs).
Current Import path
Current Import path
The Current Import path from the mDesktop Options, File Locations screen allows you to specify a different directory for mDesktop to look in for a Source File to open. When you Import a Source File or open a Source File in the Setup Wizard, mDesktop updates this path to the directory that you select the new Source File from.
Current Main File path
The Current Main File path from the mDesktop Options, File Locations screen allows you to specify a different directory for mDesktop to look in for a Main File to open. When you open a Main File from the menu or toolbar, or save a new Main File layout in the Setup Wizard, mDesktop updates this path to the directory that you select the Main File from.
Source File sub-folder
The Source File sub-folder from the mDesktop Options, File Locations screen allows you to specify a sub-folder of a "job folder" that you use for the data that you run mDesktop on. For example, if you use a standard name for a job folder of JOB12345 with a standard sub-folder name for source files of SOURCE, enter the name SOURCE in this option.
Main File sub-folder
When you save a new Main File layout in the Setup Wizard, mDesktop will default to save the file in a sub-folder of this name, either within the directory that you select the Source File from, or within the directory above that if the Source File is in a sub-folder matching the name in the Source File sub-folder described above. For example, if you use a standard name for a job folder of JOB12345 with a standard sub-folder name for mDesktop files of WORK, enter the name WORK in this option.
Temporary files path
The Temporary Files path from the mDesktop Options, File Locations screen allows you to specify the directory that mDesktop uses to store temporary files. You can specify this path when you install mDesktop, but change it at any time using this option – you must restart mDesktop for it to take effect. You should select a directory on a local hard disk – if you have more than one local hard disk, we recommend that you store temporary files on a different physical hard disk from that on which mDesktop is installed. mDesktop creates a lot of temporary files, which are usually cleaned up when you close mDesktop, but if it crashes, they will not be deleted.
DAT files path
This option specifies where the primary mDesktop data files are located. This includes, but is not limited to, the following types of information.
-
Single word lookup (Names & Words table)
-
Two word lookup (Names & Words table)
-
Business Noise Words (Names & Words table)
-
Mailsort data
-
etc.