
| Previous Article | matchIT Desktop Index | Next Article |
Multiple File Deduplication
What you have done so far is to dedupe one file. matchIT can also be used to find the common (overlapping) records across two databases, using the Merge/Purge functionality that is available in all versions except matchIT Lite.
The ability to find records common to two lists is a powerful function. It allows you to:
- Purge existing customers from bought-in mailing lists
- Merge databases from regional offices with a head office file, without creating duplication
- Transfer Data from matching records in one file to records in the other file
- Write Overlapping Records to output records that exist in both files to a third file.
All these options are available from the Merge/Purge menu. You can perform the Merge/Purge step on two databases of different structures e.g. one database may have the name all in one field, and the other split into title, first names and last name, as in this example.
If you have more than two files that you would like to Merge/Purge you can use the Multiple File Wizard (available in matchIT Pro and matchIT Campaign from the matchIT Wizard Pane). Alternatively, matchIT has the ability to work through files simultaneously in a process similar to that of Exercise 1. The Two File Wizard process is explained in the following sections.
Starting the Two File Wizard

|
Select the Two File Wizard button on the left. |
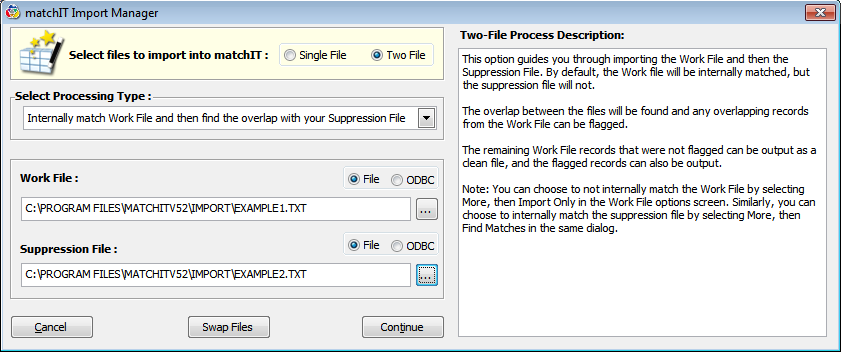
This will open a similar window to the single file process used in Exercise 1, but now you will select a second file and the process you would like to perform. Unlike EXAMPLE1.TXT, EXAMPLE2.TXT is in fixed width format, but the Setup Wizard will be able to recognize this.
For this exercise, we will Find the overlap with your Suppression File. Select that option from the Processing Type drop down. Next, open EXAMPLE1.TXT as your Work File. Then set your Suppression File to EXAMPLE2.TXT (EXAMPLE2 has no internal matches). Select Continue once you have chosen a process and the necessary files.
The next window displayed is the field-labelling window for EXAMPLE1.TXT, you may recognize this window as it is the same window used in Exercise 1. Make sure all fields are labeled correctly, and then select the Continue button.
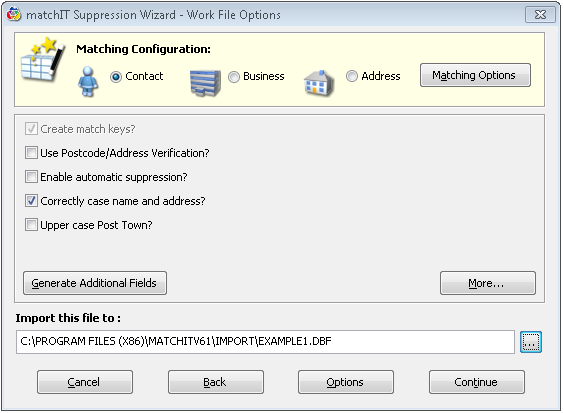
Depending on what you want to do with this file, you could select to generate salutations and/or case the data. You should select the matching level required i.e. whether you wish to dedupe to one record per Contact, Business or Address.
For this exercise, we are going to purge the records from EXAMPLE1.TXT that also exist in EXAMPLE2.TXT, so EXAMPLE2.TXT is a suppression or ”stop” file. Tick the Correctly case name & address option, and set matchIT to a matching level of Contact. Click Generate Additional Fields, tick the generate salutation field option and Save changes.
To make it clear which file is which, name this matchIT database WORKFILE.DBF by selecting the file selector button. Then select Continue.
Once matchIT has finished importing the data it will display the Matching Results window, see below. This is the same window that was displayed in Exercise 1. From here you can select to View Matches, Verify Matches, or Flag Matches. For this exercise, we are going to elect to Flag Matches for records scoring equal to or greater than 80.
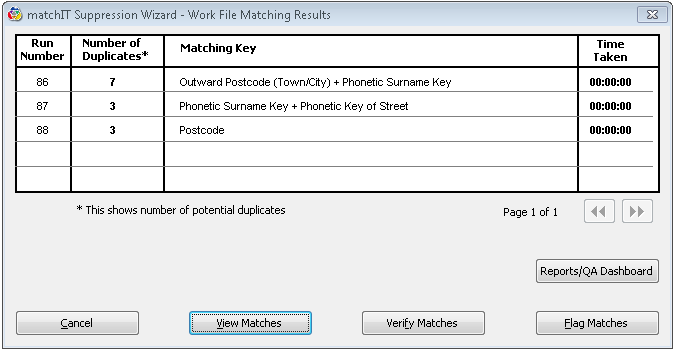
After EXAMPLE1.TXT has been imported and deduped, matchIT will begin to work with EXAMPLE2.TXT (the suppression file). matchIT will prompt the user to begin the import of EXAMPLE2.TXT, since this is a suppression file matchIT will not flag any duplicates within the file. Select Continue to begin importing EXAMPLE2.TXT. EXAMPLE2.TXT will go through a similar process as EXAMPLE1.TXT, excluding internal deduplication. Save this imported file as STOPFILE.DBF and click Continue.
Now we are going to purge names from WORKFILE.DBF that already exist in STOPFILE.DBF. This is to ensure that we remove existing customers from the WORKFILE.DBF file that we just deduped.
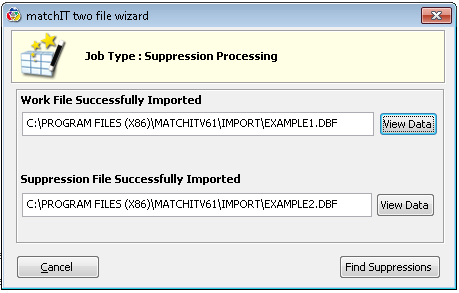
Find Suppressions
To purge the STOPFILE records that also exist in the WORKFILE, select Find Suppressions.
View/ Verify Overlap
The Matching Results window will be displayed once the overlap is complete. However, the Matching Results dialog now has different options from when you were deduping the single file:
View Overlap and Verify Overlap work in a similar way to View Matches and Verify Matches. Select Verify Overlap to see the matching pairs from the two databases:
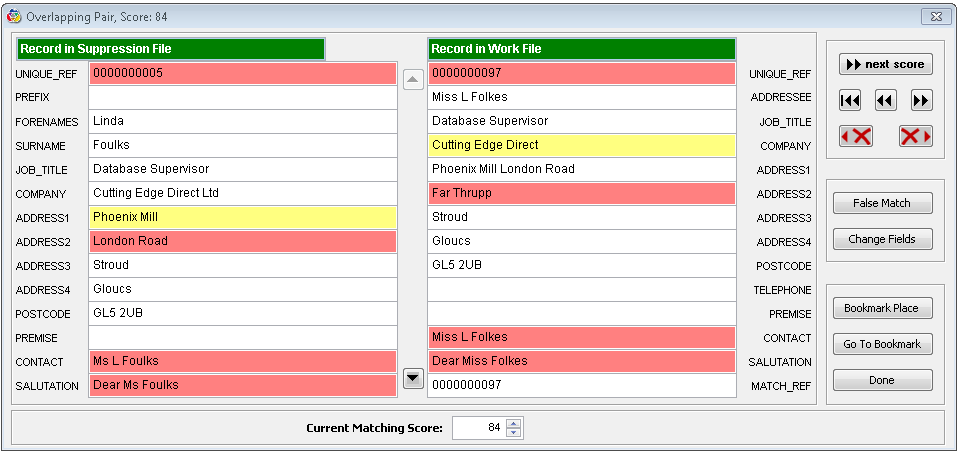
Note how the databases different structures are reflected in the layout of the screen. If there are more fields to see, you can use the central scroll bar to allow you to view the other fields. Choose Done to return to the Matching Results dialog when you have looked through the overlapping records.
Remove Suppressions
Having found the common entries between these two files, you can now select Remove Suppressions. You will then be prompted to Flag records that scored above a user-determined threshold, 80 is matchIT’s default (40 for Address level matching). The Results window will open after the records have been flagged. From here you can utilize the Reports/ QA Dashboard, output a Cleaned File, or output Flagged Records. Select Cleaned File to generate a clean file, one with no internal duplicates or overlapping records.
|
Note |
If at any stage you depart from the prompts for the usual options that the automatic dialogs display, you can select those options as required from the menus e.g. Output to File from the Output menu. |
Generating a Clean List
You can now generate a clean output file, one with no internal duplicates or overlapping records. After selecting the Cleaned File button, you will now see matchIT’s Produce Output window. From this window you can determine the file layout, format and destination as you previously did in Exercise 1. After the file has been generated, you will see a window displaying the number of records output.
QA Dashboard
In the dialogs presented automatically after the Importation of Records, or the Deletion of Matches, you will see an option to utilize matchIT’s Reports/ QA Dashboard. The Reports/ QA Dashboard is also available from the Output menu. Selecting this option results in the ability to display the Data Summary, View Records by Category and View Data within the DBF.
Select the Data Summary to view the same report as was generated in Exercise 1, but this time for the WORKFILE.DBF in Exercise 2. Scroll down or go to the next page to look at the information further into the report. This section of the report summarizes information about:
- Data Extraction
- Potential Data Errors, on records which should perhaps be excluded from the output
- Main Input Options
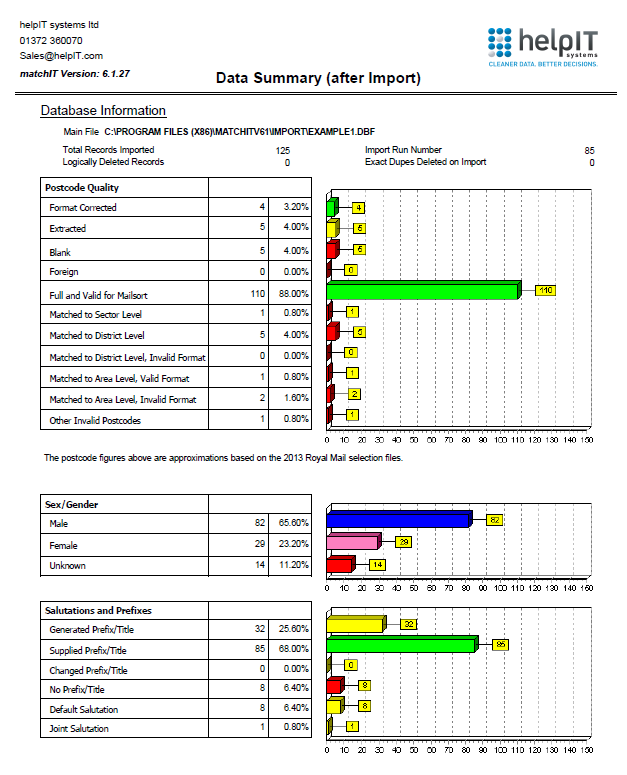
To "drill down", view various categories of records reported on the summary, close the report preview and select View/Edit by Category from the main QA Dashboard dialog.
The window displayed allows you to display all records meeting the selected criteria - most of them are categorized on the Data Summary.
You can select several categories to view at once. You can also choose to delete the selected records from this file before output, print them and/or write them out to a separate file. For this exercise, with WORKFILE.DBF open, tick Default Salutation and select Browse on screen. Select Continue, then Continue again on the next dialog to view any records for which matchIT could not derive a proper salutation e.g. records with no contact name, no prefixes with unisex first names and inconsistent first name and title e.g. Joanna Gifford Esq.
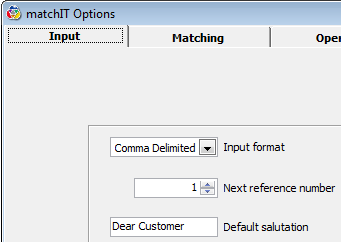
The Default Salutation shown is Dear Customer, but you can change this from the Setup menu, Options, Input tab, or from More options at the end of the Setup Wizard.
After you view the selected records, matchIT returns you to the View Records by Category screen to select more categories if you wish. To leave this screen, select Close.
Next, select View Data button (in the upper right) from the main QA Dashboard dialog. This displays the Browse Customer Database dialog. You can view matchIT databases in order of any field, click on Order Records then click on Continue. On the next dialog, scroll to the bottom of the field list and double click on Salutation as the field on which to order the new view.
In the data window shown, scroll towards the right. matchIT has added several fields after the last field from the original data - these are the phonetic and other key fields used by matchIT to search for matches. At the end, you can see the generated Contact and Salutation fields. matchIT has derived the Contact field from the supplied name, and worked out the correct Salutation. By viewing the data in order of a field, you are more likely to see unusual and perhaps suspect values of that field near the top of the data, which is a very useful Quality Assurance technique.
If you scroll down the list, and compare what’s in these fields against the input name fields, you will see how matchIT deals with complex and uncommon name structures, even when an input file has the contact name within one field.
Press Escape to close the view, and then choose the Output tab from the main Reports/QA Dashboard dialog. The next dialog allows you to output 1 in N samples and selections of records. Select Close to close the Reports/QA Wizard.
| Previous Article | matchIT Desktop Index | Next Article |