
| Previous Article | matchIT SQL Index | Next Article |
So ideally we already know how to set up a key generation step. Otherwise, go back here:
Up until now we’ve only gone over internal dedupes. Now let's get into an overlap, or matching across two datasources.
1) If we go into SSDT – we’ll see we have a generatekeys step that we set up previously against the example1 tables that are in the matchIT_SQL_demo database that gets created during install.
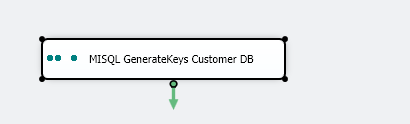
2) We can see that it's already mapped to the example1 table – which we’ve previously gone over how to set up previously
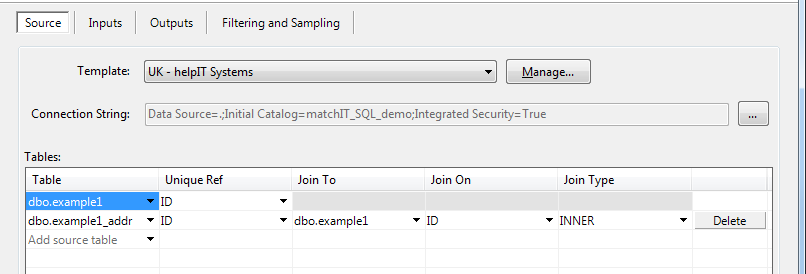
If you take a look at the input mappings, you'll recall that there's a fullname, and 4 address lines in that data.
3) Now let's drag and drop another generate keys task. Give it a more appropriate name
Open it up and go through mapping it to example 2
A) Pick your template- Ideally the non-default one you made earlier and are using for your first table, set up your connection string
B) set your input tables

C) Click next and set your input mappings

Here we have a prefeix/forename/surname and 4 address lines; if you had more or less address lines you wouldn’t need to do pre-processing to line the data up. Although if you do have our addressing module we do suggest standardising the addresses before, but it’s not necessary.
4) Now that we have two generate keys tasks, we can do an overlap, drag a findoverlap task and connect both tasks to the one findoverlap task
5) open up the findoverlap task
By default, we will choose the larger table as the source table
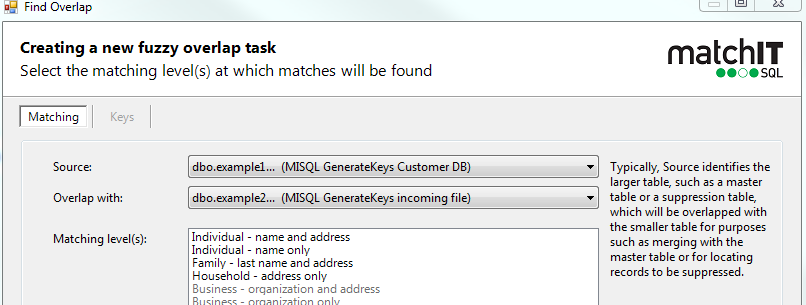
Note the explanation of main vs overlap. If you think your tables should be the other way around, now would be the time to switch them. You can see the results and come back and switch later if unsure, but it's best to get it right now as we fill in the table names based on main vs overlap.
6) In order to continue – you must choose a matching level and a matching keys volume, in that order.

If the matching level you want is grayed out, it means you likely didn’t map something in one of the generate keys tasks.
7) For now we’ll stick with the defaults, those work for 85% of clients, although as a matter of practice, we suggest breaking out the component scores.
So click ‘show advanced options’ in the bottom left – and you’ll see component scores, click that – and break out the name, address and postcode scores if you’re doing individual/family, break out the organization, address and postcode if doing business, or just the address and postcode if you’re doing household.
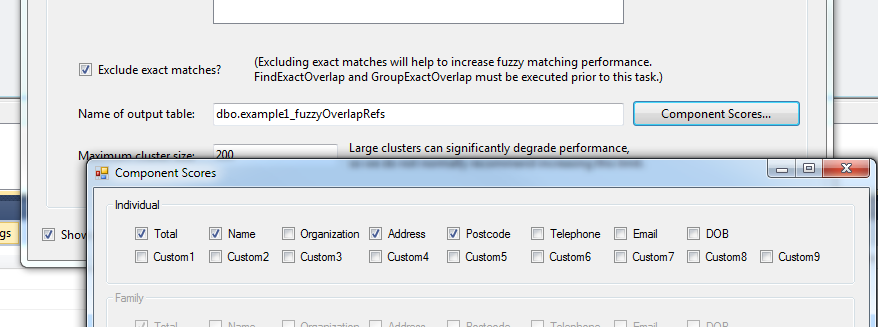
Breaking out these scores can help you understand why something matched if you’re more familiar with SQL, or more so we ask as it normally makes troubleshooting easier for your support rep.
8) You can see the keys tab and advanced tab by click up top or click next, it fills in different default keys for you based on your matching level, but for now let's leave those alone and just save the task.
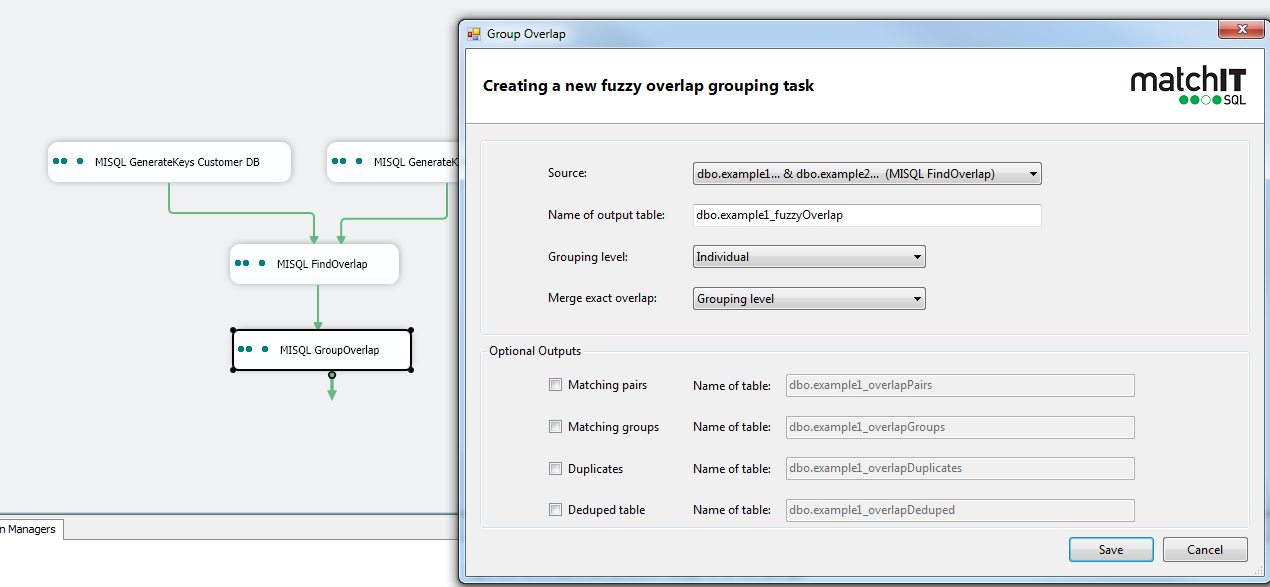
9) Next let's grab a group overlap task, connect the find overlap task to the groupoverlap task
The table name and matching level should be read in from the previous task, if you don’t connect the tasks in the expected order, you may see strange behavior.
We suggest outputting matching pairs and deduped tables, that’s what most end users end up utilising the most.
Save the task and run the package.
10) Once complete, let's take a look at those 3 results tables. (you may need to refresh tables in SSMS before you see them)
The matching pairs as you can see, is a side by side of the records that matched. You’ll see ID_1 which is from the source table, and ID_2 which was the ID from the overlap table, as well as the score. So if you need to append data from the main to the overlap datasource, this gives you the linking references you want to use.
As a note – if you’re a more advanced user, you may be more interested in the raw data – which is in the fuzzyoverlap_refs table.
If you look at the Deduped table, these are all the records from the overlap datasource that didn’t match to the main datasource.
| Previous Article | matchIT SQL Index | Next Article |