
| Previous Article | matchIT SQL Index | Next Article |
Company Only Matching
When matching on company name only, we normally start out with first switching to 'tight' business matching settings referenced in the previous article, here's a brief rundown of those changes.
- In generatekeys
- change 'use equivalent name' to true for organization
- change to use the \tight names and words
- change 'normalizationtruncation' to 9 in the further settings
- (less commonly changed) in the template xml, switch to the 'tight' matching matrix,
- If you want to be very strict and also minimize false positives, then use the 'legal' organization matching matrix along with the default names and words but still changing the normalizationtruncation and 'use equivalent name' to true
The key generation will normalise the company name
ie:
360Science inc
360science
corporation of 360Science
Although without an address to line up records - it would be difficult to line up other instances
such as:
Acronyms:
ie: AMA , American Marketing Association
Transposed data:
360science corp
Corporate Headquarters - 360science
Starting with version 2.3.1, we've added additional keys to help make these comparisons when there isn't an address available that would normally make it easy for our matching engine to catch that.
Company Specific key added in 2.3.1:
mkOrgAcronym – Letters of NormalizedOrganization
mkNormalizedOrg1- First part of NormalizedOrganization
mkNormalizedOrg2- Second part of NormalizedOrganization
mkNormalizedOrg3-Third part of NormalizedOrganization
mkAlphabeticOrganizationWordA – The alphabetically first Organization word.
mkAlphabeticOrganizationWordZ– The alphabetically last Organization word.
Also starting with 2.3.1 the default keys will now include these two
mkAlphabeticOrganizationWordA
mkAlphabeticOrganizationWordZ
Considerations for company only matching:
Adjusting the score:
By default the company only minimum score is set to 60, requiring a 'sure' match, many clients wanting to see additional matches will lower it to 40 by clicking the 'advanced' on findmatches/findoverlap and adjusting the minimum score and still be happy with most of the results.
If you lower the minimum to 25 or 0 they will get progressively fuzzier (0 meaning it lined up on the keys but we're not confident in it enough to score, normally the only time we advise lowering to 0 is to be used for troubleshooting to find out if its being compared by the keys in the first place).
More advanced users will also adjust the scoring in the matching matrix xml, so that instead of a 60,40,25, you can set a particular pattern to score .9 of sure (.9 * 60 = 54)
-to expose the matrix entries so you know where you need to adjust, you need to enable the outputcompareresults setting in the template xml - see more here
-to see an example of using a decimal value in in a matrix entry, see more about the match scoring here
Performance:
If your main goal is performance - we would suggest suggest starting with the Tight keys as well as removing these 2 additional new keys, or at least the mkAlphabeticOrganizationWordZ as we've seen it can cause long run run times in comparison to the quality of the results returned.
mkAlphabeticOrganizationWordA
mkAlphabeticOrganizationWordZ
Seeing any possible results:
If your main goal is to be presented with as many results as possible so that you can manually review them, you can leave those keys metioned above in there, as well as adjusting the score, you can adjust what's compared in the first place
You may consider add some additional keys such as mkOrgAcronym, or using a left or right function on the input Organization or mkNormalizedOrganization
Using the key to sort the results in addition to the score:
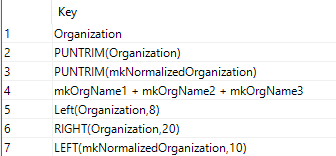
While the order of the keys does not impact the end result, it is recommended to use the keys in an order of tightest to loosest (strict to fuzzy) , so that when reviewing results you can sort them not only by score, but by key, allowing you slightly more granularity in the results. In some cases - especially with company only matching, some clients will sort by the key first, then the score.
So in this case - we consider 'Organization' more strict than PUNTRIM(Organization), followed by PUNTRIM(mkNormalizedOrganization), then we get into the mk fields or just the first or last x characters of fields.
This technique is more effective when overlapping across 2 files, but if you look at the result table from findmatches or findoverlap you'll see the additional information, and it would be suggested to include the pairs output from groupmatches or groupoverlap which will make the matching_pairs_and_scores or overlap_pairs_and_scores tables respectively.
So in above case, we may automate the results from keys 1-3, but then send the results from keys 4-7 for manual review. That can vary depending on your requirements and volumes as well as whether you're running exact matching/exact overlap first.
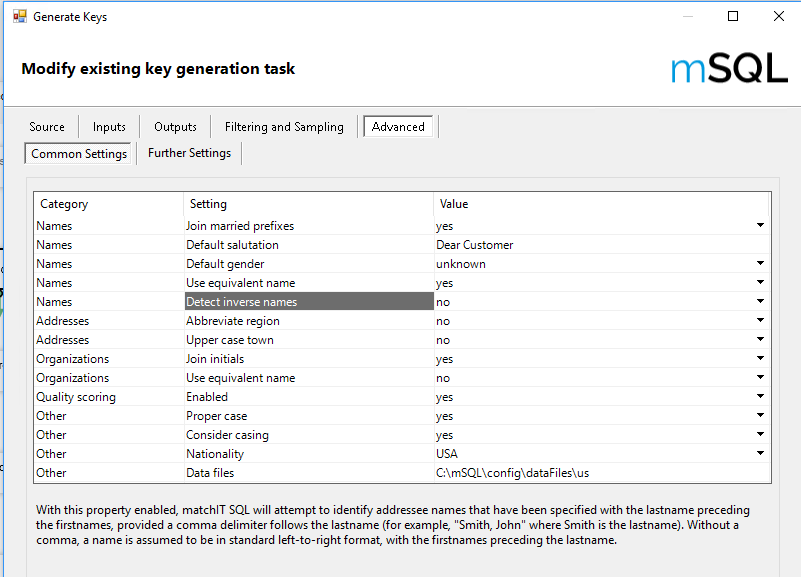
For Contact Name only matching, the most common setting changed is the 'detect inverse name' being set to yes, depending on whether you have lastname,firstname info stored that way.
Name Specific keys added in 2.3.1:
FirstNameIni – First letter of first name
NormalizedFirstName – Normalized First Name
NormalizedMiddleName – Normalized Middle Name
NormalizedLastName – Normalized Last Name
Additional key fields added to be in line with our findIT S2 product:
Telephone - Telephone
Email -Email
EmailUser - User of the email (bit before the @)
EmailDomain - Domain of the email (bit after the @)
Now when matching on a company / name only, you are significantly limiting yourself, as our matching engine is designed to look around differences and see how as a whole that two records go together, without an address or other relevant information it limits our ability to make logical comparisons when the company/Name is different.
| Previous Article | matchIT SQL Index | Next Article |