
| Previous Article | matchIT SQL Index | Next Article |
1) Go to an existing key generation task (below assumes your table has a telephone field in it)
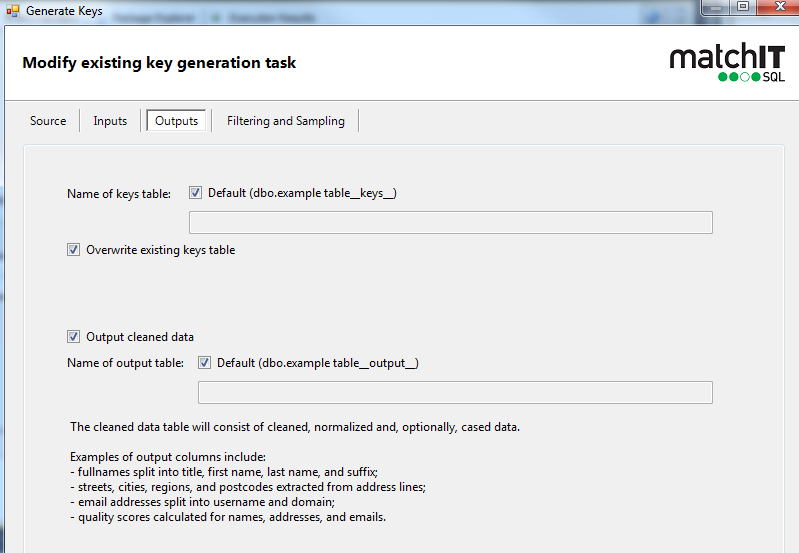
2) Go to the outputs tab, click to enable outputs
The output table gets created at the same time as the key generation
3) Click advanced, go to the advanced tab
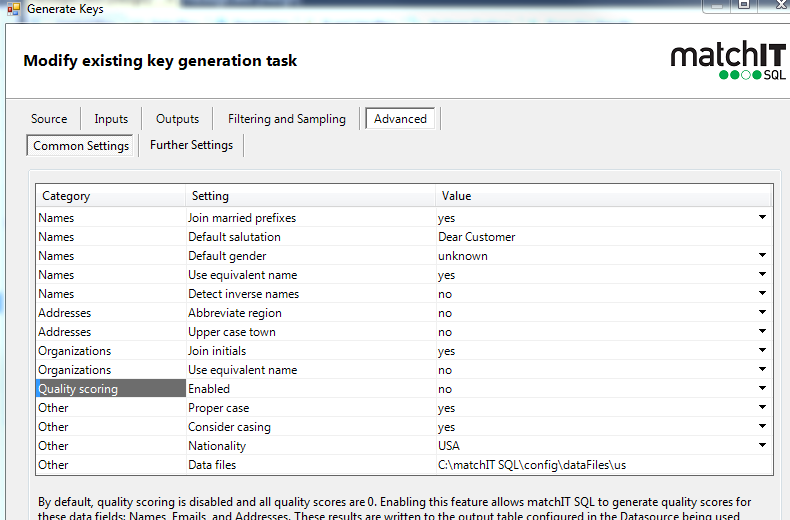
Where it says quality scoring – enable it, we suggest leaving the rest of it alone.
The other one people commonly change is the ‘consider casing', but that’s only if your data is always in CAPS, otherwise we might falsely assume something is an acronym when it isn’t.
set abbreviate state to true
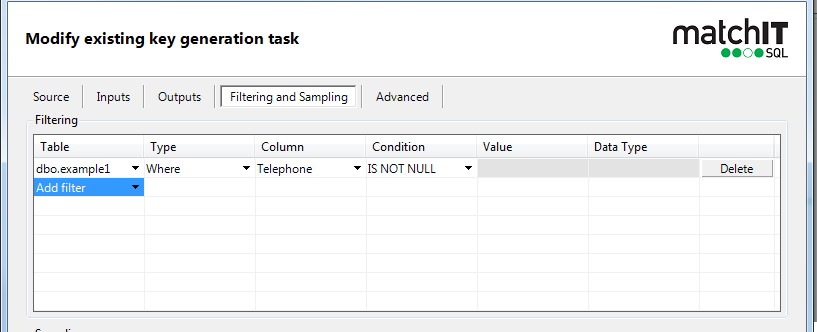
4) Go back to the filtering tab, set to do on email only as ex, then delete
Here you can control what records are used for the key generation. So if you only wanted to generate keys on records that had a telephone field that isn’t null (please note though that this means a null value rather than just a blank field) Or you could have a deleteflag field such as in the overlap demo package which would only generate keys for records which are not populated with a 1 to indicate that they are duplicate records.
If you have a more complicated filter you need to apply, it may be better to select that subset into a separate table, or use a view instead.
See the end of this section for in-built sampling options, but again, if your a comfortable SQL programmer, then using a view may be more convenient.
5)Save the task and run it.
Here are some things an output table could possibly produce for you:
- show a name parsed out
- show a company that was all caps as a proper case
- show a extracted address elements such as premises and thoroughfares
- show a postcode that was extracted
The best way still to correct and parse an address is through our address validation module - addressIT,
Other Items:
- show email parsed
- show email that has varying quality scores
Here's a key of the Email Quality Scores:
0 = empty, nonsense
1 = invalid format
2 = invalid top-level domain (com, org, uk, fr etc.)
5 = generic username (sales, support, postmaster etc.)
6 = username doesn’t match the firstname & lastname from the Input fields
7 = webmail domain (eg. Hotmail.com, mail.com) if WebmailFiltering is enabled
9 = neither of the above apply
Sampling
You may also have noticed the sampling functionality on the Filtering and Sampling tab. A summary of the available functionality is detailed below:
Sampling allows you to specify a specific sample of data to use during your processing rather than the complete datasource. This can be useful if you are testing your scripts and refining matching settings.
There are several sampling options available:
- Percentage – uses a percentage from your datasource. For example, if you select 10%, then 1 in 10 records from your datasource would be used.
- NinM - uses a sample based on N in every M records of the source data.
- Range - Uses a sample over the specified range of the specified field.
- RandomN - Uses a sample of N randomly selected records from the source data.
- MaxFromTop - uses a sample of the top N records from the source data. If this option is applied with any of the previous options, then the limit setting is used as a restriction on the maximum number of records that will be used in the sample.
When sampling is enabled, only a sample of your data will be used by the matchIT SQL; remember to de-activate this when you are ready to process your complete datasource!
| Previous Article | matchIT SQL Index | Next Article |