
| Previous Article | matchIT SQL Index | Next Article |
Previously we set up a find matches with the defaults, all of below also applies to the findoverlap task
Let's jump into that setting and some advanced options, such as getting more granularity in our results, using non-default keys, changing the minimum score, and adding a weight to an additional field like telephone and email.
Before you can incorporate telephone or email into a match for example, you need to map it back in generatekeys, so if you haven't already, then go back and map those fields before getting started. If you're using our example1 data, you can just map telephone.
1) open up find matches – click show advanced options if its not already ticked.
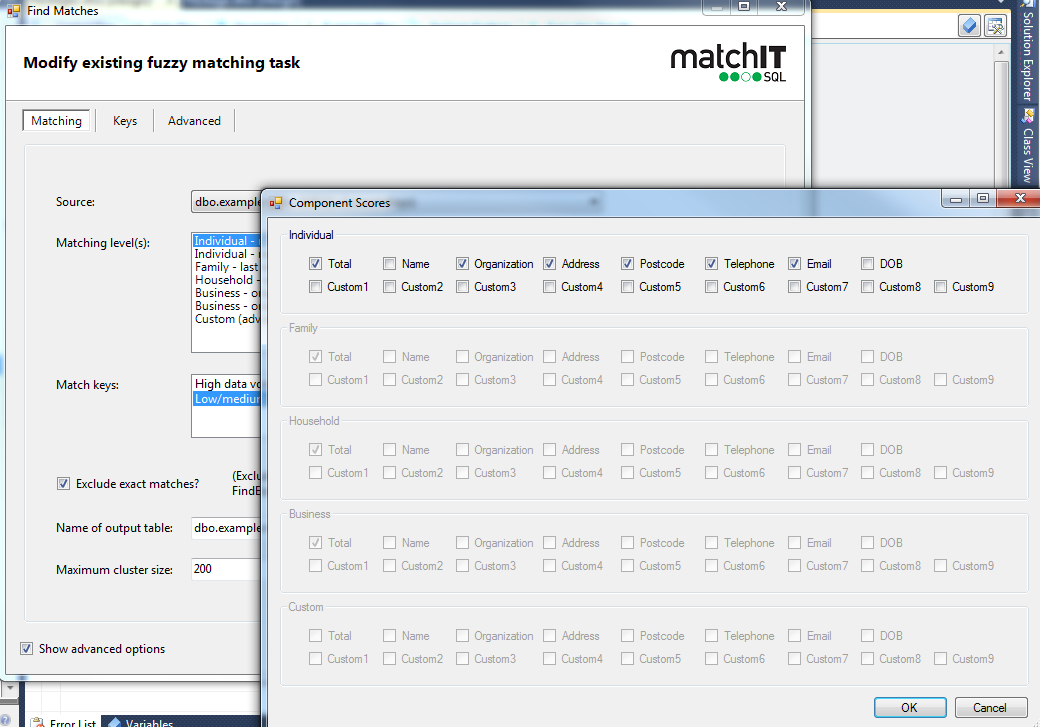
The first thing we recommend is clicking component scores, for whatever level you’re on, we suggest breaking out the scores for the individual elements
for individual or family, it's name, address, postcode
for household, it's just address and postcode
For business, it's organization, address and postcode
You can also show the score for any additional fields as well, such as telephone or email or a customfield if you plan on incorporating it into your match.
2) Next, let's go to the keys tab, there’s two things you could do
A) Tighten up existing keys – if you find matching is running too slow, it could be because you have inefficient keys, you could make the keys more stringent by changing mkname1 to mknamekey which is the same as mkname1 plus the first character of mkname2 which is the phonetic version of the forename.
alternatively, the simplest approach may be going back to the previous screen, clicking high data volume, then returning to the keys screen and refreshing, then we'll fill in some tighter default keys for you and overwrite the existing ones.
B) Alternatively, you could add more keys if you think we’re missing matches, by adding a key like email you would force us to compare all records with the same email
with telephone – use the mkfields, as those are already standardised. Please note that these are generated by default. To enable these, open the generatekeys task, go to the output tab and select 'Key columns' and enable the TelAreaCode and TelLocalNumber options. Theses will then appear in the list of keys displayed as in the screen below.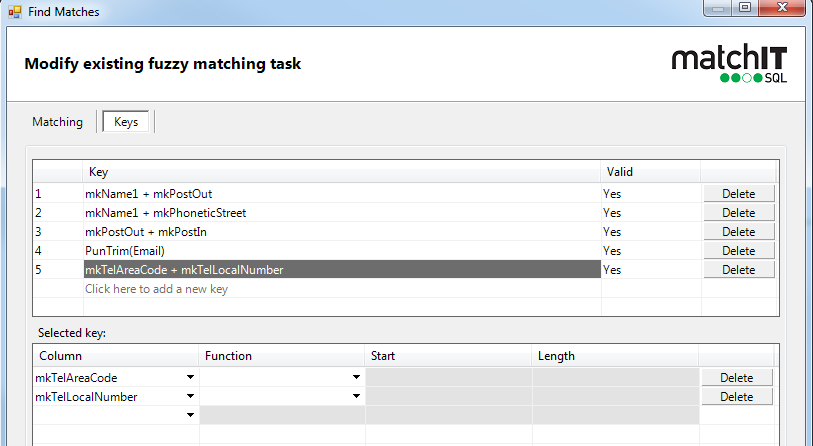
The default keys work for our clients about 85% of the time, otherwise normally a subtle change like adding one or two keys, or modifying an existing key is all that’s necessary.
Remember, our matching works in a two step process
We use the keys to find groups of potential matches because trying to compare every record to every other record is inefficient. Then as a second step we compare and score those groups of potential matches and test them against our constraints before we present it to you.
3) Now lets go to the advanced tab
Here you’ll the threshold scores for the level of matching you have selected and the weights and constraints for each. It is possible to run multiple levels at the same time, although for simplicity we will suggest running one level at a time. There are other considerations when running multiple levels, such as adjusting your exact matching keys to make them more appropriate for multiple levels depending on your data and matching requirements.
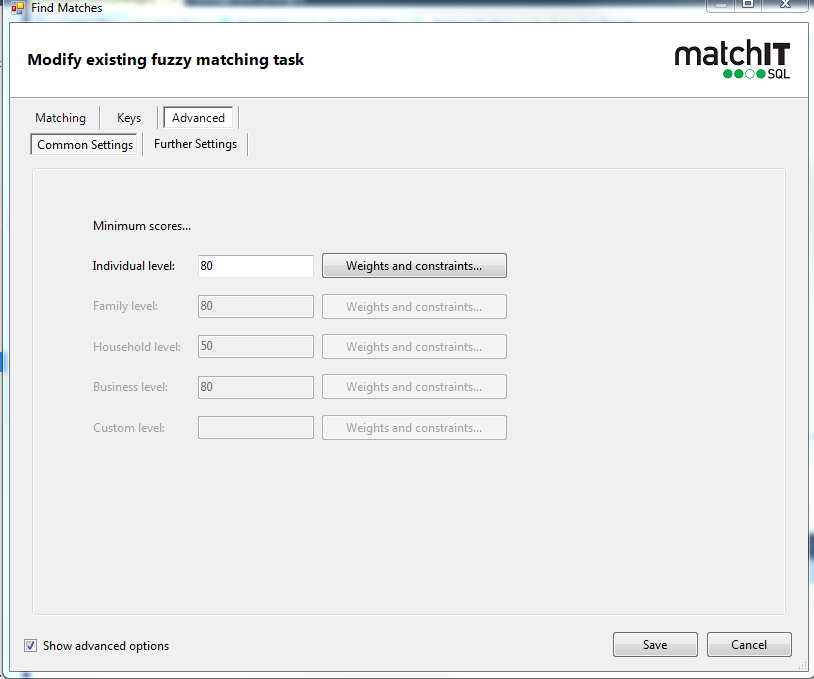
By default, something has to score 80 in order to count as a match on individual, business, or family level, or at least 50 for a household match, or 60 for a name only/company only match
If you want to get less fuzzy matches, you could raise the minimum score to 86 or 95 for example, whereas if you wanted more fuzzy matches you could lower the score to 71 (we wouldn’t suggest lowering the minimum to 70 or below as that will likely be too fuzzy)
for household, you may raise the minimum to 55, or could lower it to 40 for fuzzier matches.
for name only/company only(which would be used instead of individual/business), 60 is the default high score, raising the minimum any higher will prevent all fuzzy matches from showing up, but you could lower it to 40 or 25 to let in fuzzier matches.
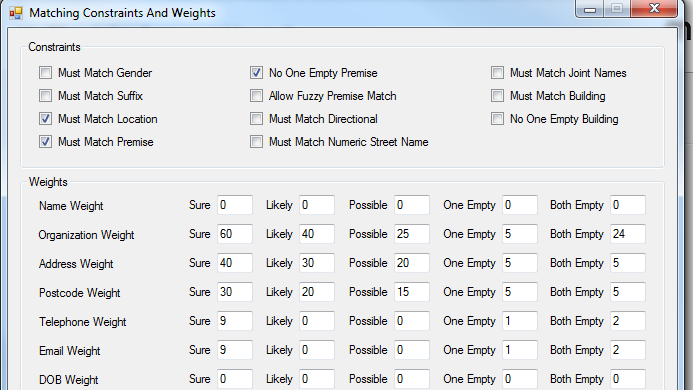
4) The next thing is weights/ constraints (in below screenshot we're using business level )
Lets start out with the 3 most common constraints –
Here you’ll see constraints along the top - Must match location, must match premise, and no one empty premise
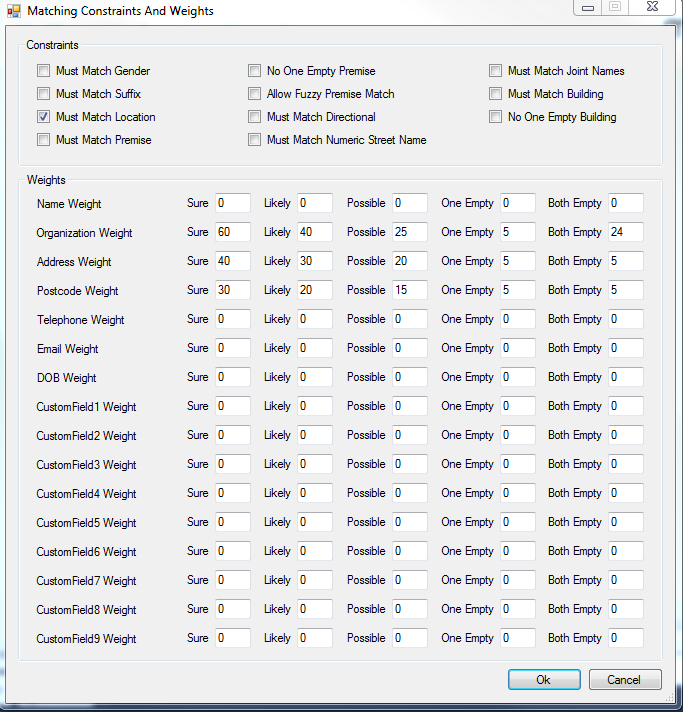
Must match location
When this property is set to True, potential matches will be disregarded if their address
locations differ. In detail, this means that the postcodes in the two records (if present)
must achieve at least a probable match with the address score at least a Possible match,
or the address score must be at least a Likely match irrespective of the postcodes, or the
postcodes must achieve a Sure match irrespective of the address. This is to prevent false
matches where there is some match on address, but where the addresses are clearly not
the same.
You could turn off must match location (but that may let in false matches , we leave it on by default for most matching levels)
Must match premise
When this property is set to True, potential matches will be disregarded if their premise
numbers differ. If however the premise number is unknown (e.g. one record or both
records may contain a premise name), the records will potentially be classed as a match.
This is normally the easiest way to reduce false matches if you want to automate your process, we’d suggest this as the first change to make if you see matches like above and don’t want them.
No one empty premise
When this property is set to True, potential matches will be disregarded if one of the
addresses is missing a premise number.
These are the 3 most common changes users will make, its much easier than playing with the keys. This all applies to individual level as well if you were to use a person's name instead of a company name.
For family level, we'd suggest enabling must match premise as well in most cases.
For household level, we enable more constraints by default since we remove the emphasis on name when it comes to scoring.
5) Modifying the Weights
Just as an intro, we’ll add a small weight to telephone and email for example.
We suggest leaving the weights mostly alone, or only making subtle changes until you understand them better. We’ll get into the scoring more later on, or feel free to reach out to support for more advanced questions.
So, in this case, I’m going to add a weight of 9 to the sure score for both email and telephone.
By adding a weight to the sure score, they will get those points if both records have that field exactly the same, this is a cumulative score so the email score would be added to what it scored on name/company/address/postcode.
If you add a weight to the likely or possible scores, that will allow matches that have one or two transpositions respectively. At this point we would recommend not adding a likely or possible weight to telephone, as that could lead to false matches possibly as phones are less unique than email frequently.
The one empty and both empty scores are if the telephone or email are not populated in one or both records. Some people like to identify that kind of information pattern and may put a small weight of 1 or 2 points in one empty/both empty. You can only see this information if you broke out the component scores like advised at the beginning.
As a note, you can also apply a negative weight if you wanted records to not match based on some field being the same.
Click ok and save when done.
| Previous Article | matchIT SQL Index | Next Article |