
| Previous Article | matchIT SQL Index | Next Article |
Exact matching isn’t always necessary but is normally suggested as it’s an easy way of improving performance in most cases.
When should I incorporate exact matching?
- You have a large number of records that are exactly the same – matches found by using exact matching improves performance because these records are not compared like potential matches found using fuzzy matching
- more granularity in results – exact matching provides an extra tier of scoring, so even if a match scored 120 (the highest score with our defaults) – an exact match would be an even better match than that, instead of being mixed in
- you want to match on a single field, such as an exact email match, or an account number or invoice that would normally not qualify as a match from a fuzzy perspective
Why shouldn’t I run an exact match
- exact matching selects all the columns and their data into memory, this may be slow depending how large your table is and how much tempdb space is allocated on your SQL instance
- you have lots of blank fields or junk in your data, in which case the exact matching will skip over most matching due to the columns not being ‘optional’ by default, or may over report matches that normally would be skipped, we expect the data to be well populated by default.
As a note, anything found by an exact match is removed for processing for the fuzzy match, so if you're too aggressive with the exact match by say doing an exact match on email, you could just end up introducing false positives if your data isn't clean. We normally recommend a single exact match key, that encompasses all the significant data points.
Let's add exact matching to a process we set up previously.
1) Exact matching should be run between generate keys and findmatches – there are two tasks that would need to be added
Findexactmatches
groupexactmatches
2) Assuming you're editing the package from the previous article, the first thing you'll need to do is delete the connector between generatekeys and findmatches
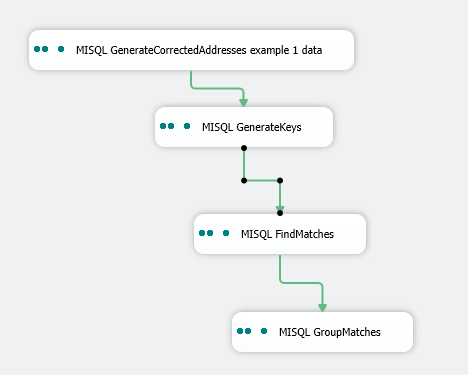
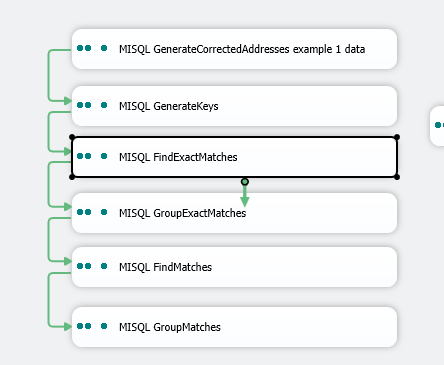
3) Drag and drop the tasks, connect them in the order like below. You can highlight and arrange using the format menu above, you make them the same width then center them, although if you want to rename the tasks you should do that before.
4) Open up findexactmatches – notice it reads in the task from the previous source
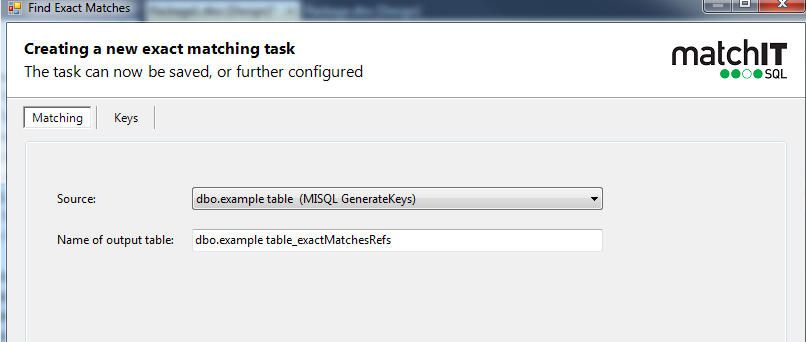
5) If you want to use the default key, you can just save and skip to step 12,
depending on your data though, we would suggest making some alterations, which is covered in the next step
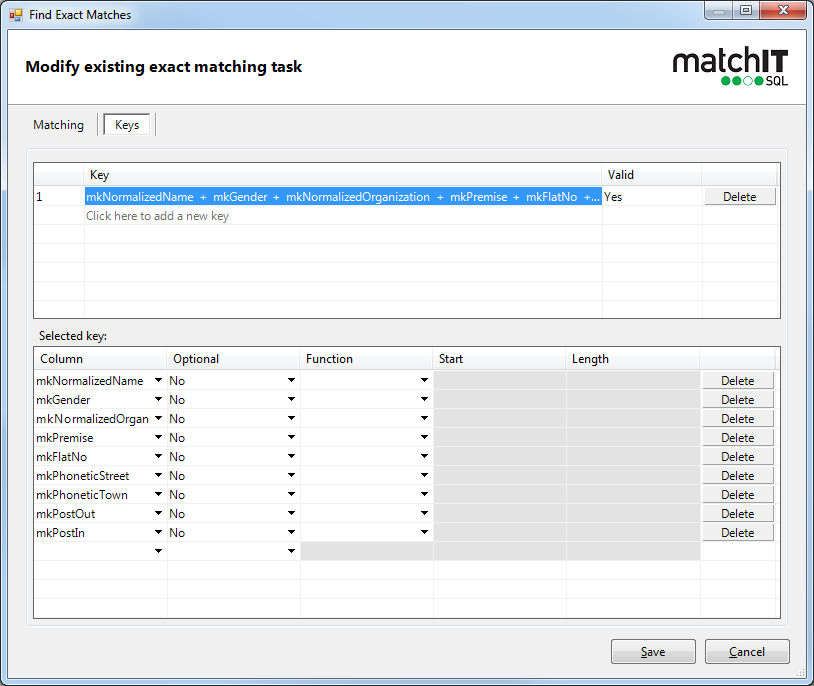 Notice up top that a single key is listed, unlike the fuzzy keys where its only one or two fields, this concatenates a majority of the key fields.
Notice up top that a single key is listed, unlike the fuzzy keys where its only one or two fields, this concatenates a majority of the key fields.
Anything that starts out with an mk is a matchkey field, and has already been standardised by matchIT SQL. You can think of the list of columns within a single key as ‘AND’ statements, whereas having multiple keys up top are like “OR” statements
6) In this case we’ll stick with the single key, but if you have company data without contact details then you should remove the mknormalizedname and mkgender key because this key field will always be blank and if both records are blank for any of the keys listed, they will be prevented from matching as exact matches. Likewise, if you only have individual names in your data, you should remove mknormalizedorganization. In both cases above, we also suggest making the mkflatno optional. Making a key field optional means that you allow records where this field is blank in both records to still match, note however that if only one record is blank, they will still be prevented from matching. Flat numbers are often empty in UK addresses so if you don't make this optional, many otherwise exact matching records might be missed.
7) If you wanted to do an exact email match or additional exact match keys, you could also add that – but we’d suggest you QA your results if that’s the case, or at least not choosing yes on the ‘optional section’, having a match of email only may cause false positives if you had say two different people with an info@helpit.com, so either stick to the one exact match key and more easily identify that during fuzzy matching (reccomended), or make the key more concise by adding name in addition to email as part of the exact key.
8) Save the task
9) Open up groupexacmatches, confirm the table names are correct, then save it, no other changes are needed.
You can also control the setting for master record identification by checking or unchecking the 'Identify best record in group' option. For more details on master record identification please click here.
You can also optional chose to enable 'Exclude duplicates from further processing'. This option will prevent any records that were found as duplicates, from being included in any further processing, by matchIT SQL SSIS tasks that may follow. E.g. this option would prevent duplicate records from being included in Mail Sortation or Output. Also, duplicates would not be uploaded to the Hosted Service by the HostedService task, and would not be included in any further matching analysis should any additional matching or overlap tasks follow this task.

10) Open up findmatches – change the source to group exact matches (this isn’t needed if you are starting a new find matches), also ensure that ‘exclude exact matches’ is ticked
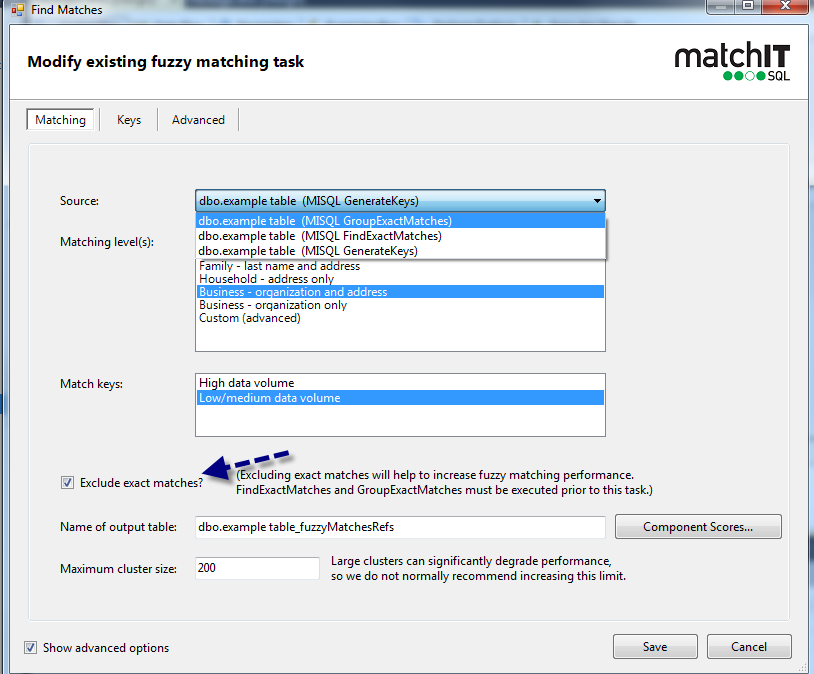
11) Open up groupmatches
set Merge Exact matches to ‘all matches’, save (always set it to all if you're not using the default exact key)

Exact matching is now incorporated into your process.
| Previous Article | matchIT SQL Index | Next Article |