
This section is for users who wish to customize mDesktop's matching setup. We recommend that you have some experience with mDesktop before changing the default setup.
Basic Matching Options
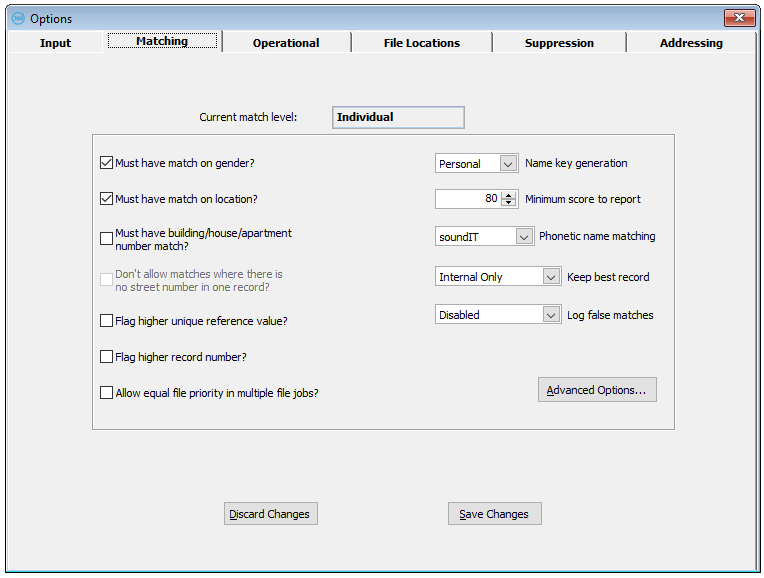
Must have match on gender
If you set this parameter "on", then matches where the sex is different (where the sex is normally deduced from the title) will be suppressed, even if the name matches and there is no independent confirmation of the sex by the forename. Note: even if you have this parameter off, mDesktop will always return a nil score on name (if you are not doing family matching) if the sex of the two records is different and is independently confirmed by the sex deduced from the forename of each record.
Sex is only regarded as different if one record must be Male e.g. Mr and the other Female e.g. Mrs, so it will match Mr and Dr, or Mrs and Dr etc. but not Mr and Mrs.
Must have match on location
If this parameter is set "on", then a matching pair is not reported if a 'location check' has failed. In detail, this means that the zip codes in the two records (if present) must achieve at least a probable match with the address score at least a Possible match, or the address score must be at least a Likely match irrespective of the zip codes, or the zip codes must achieve a Sure match irrespective of the address. This is to prevent false matches where there is some match on address, but where the addresses are clearly not the same, for example "10 High Street, Bookham", and "10 High Street, Alford". Switch this parameter off if you want to match people or companies in different locations; you may want to match on items of data that are independent of location, such as date of birth or bank account. See also the section about Address Matching.
Must have building/house/apartment number match
If you set this parameter "on", then matches with different premise or apartment numbers in the addresses will be suppressed. This could be appropriate if you have a very localized file with a lot of neighboring records, perhaps with similar names.
Don't allow matches where there is no street number in one record
If this parameter is "on", then matches where one of the records has a premise number in the address, and the other hasn't will be suppressed. This is useful when your file has a lot of addresses with house names in the address lines. Note that this parameter has no effect if the "Must have premise match" parameter is off.
Flag higher reference
This specifies the default rule for global flagging of matches, when the deletion priorities are equal or switched off (see Keep best record below). If you set the Flag Higher Reference parameter "on", the record with the higher reference number from each pair is flagged by the Flag Matches option; otherwise the earlier record in the file is flagged.
Name key generation
This parameter governs how the NAME1, NAME2 and NAME3 Match Keys are generated; if the parameter is set to 'Personal', the keys are generated from the personal name, if it is set to 'Business', they are generated from the company name (See the 'Phonetic name matching' parameter below). If you want to switch from any other type of matching to business matching or vice versa, you should do so by using the Save/Restore Setup (see Online help for more information on Save/Restore Setup) option, rather than by just changing this parameter. This is because business matching uses different matching rules to other matching levels.
Minimum score to report
The Minimum Score to Report is the minimum matching score necessary to allow the records to be reported as potential matches. These records are written to the Matches table (or the Merges table for Find Overlap processing).
Phonetic name matching
There are two stages to the matching process that mDesktop uses; the key stage and the scoring stage. The first stage creates standardized and phonetic keys based on the input data, which allows potential matches to be identified. The second stage scores each pair of potential matches, using phonetic and fuzzy matching. This parameter governs the phonetic algorithm that mDesktop uses when generating keys and for scoring.
There are three choices available:
- soundIT
mDesktop provides a unique phonetic algorithm for name matching, called soundIT. soundIT takes account of vowel sounds and syllables in the name, and, more importantly, determines the stressed syllable in the word. This means that "Batten" and "Batton" sound the same according to soundIT, as the different letters fall in the unstressed syllable, whilst "Batton" and "Button" sound different, as it is the stressed syllable which differs. Another advantage of soundIT is that it can recognize groups of vowels and consonants that form vowel sounds – thus it can equate "Shaw" and "Shore", "Wight" and "White", "Naughton" and "Norton", and "Leighton" and "Layton" (which are all reasonably common English surnames).
This algorithm was developed with extensive testing on a large table of the most common surnames in the UK. Therefore, it is specifically designed to be used with English names. If a file with mostly non-English names is processed through matchIT, then you may want to try the 'Loose' soundIT or Soundex algorithms instead. For US data we recommend that you use soundIT, because it is proven to work well also with Spanish, German and other names that occur commonly in the US. soundIT has been designed with foreign language versions in mind (i.e. for data collected in countries where foreign languages are spoken). These could quite easily be developed, according to demand. Please contact your supplier if you are interested in this.
Note that the keys that mDesktop generates are 'Loose' soundIT keys, where all vowel sounds are equated, together with some consonants, such as 'm' and 'n', 'd' and 't', 's' and 'f'. This is so that potential matches are not missed at the key stage; mDesktop uses the 'full' soundIT algorithm at the scoring stage, which will separate out false matches from true matches.
- Loose soundIT
This option is effectively the same as the soundIT option, except that mDesktop uses the 'Loose' soundIT algorithm as described above at the scoring stage. This is for use mainly with non-English names, on which soundIT works less effectively, and can miss true matches. This option should not be used on files with mainly English names, as it can potentially lead to more false matches.
- Soundex
Soundex is a widely-used algorithm (patented just after the First World War!), which constructs a crude non-phonetic key by keeping the initial letter of the name, then removing all vowels, plus the letters H, W and Y, and translating the remaining letters to numbers. It gives the same number to letters that can be confused e.g. 'm' and 'n' both become 5. It also drops repeated consonants and consecutive letters that give the same number e.g. S and C. It only takes the first four characters of the result, or pads it out with zeroes if it is less than four long. Thus all the common spellings and misspellings of the name "Tootill" equate to the same Soundex key: Tootill, Toothill, Tootil, Tootal, Tootle, Tuthill, Totill are all translated to "T340".
The algorithm that mDesktop uses is an enhanced version of Soundex, and is for use mainly with non-English names. This option should not be used on files with mainly English names, as it can lead to false matches e.g. Brady, Beard and Broad get the same Soundex key.
- Non-phonetic
This option constructs a non-phonetic version of the supplied name fields as match keys and allows only non-phonetic name matching.
Note that, at the scoring stage, mDesktop performs name comparisons using data from the NAME field, not from the phonetic keys NAME1, NAME2 and NAME3 – this way it can check for simple typing errors such as "Wilson" and "Wislon" which do not match phonetically.
Keep best record
This parameter governs the use of deletion priorities (see Online help), where mDesktop makes a decision about which is the 'best' record to keep from a matching pair e.g. the one with the most data. There are three settings: Disabled, Internal Only, and Internal and Overlap. Set the parameter to Disabled if you don't want to use deletion priorities, and want to use default rules (see the 'Flag Higher Reference' above). Otherwise set it to Internal Only, where deletion priorities will be used on matches in a single file, or Internal and Overlap, where they are used on matches in a single file and across files.
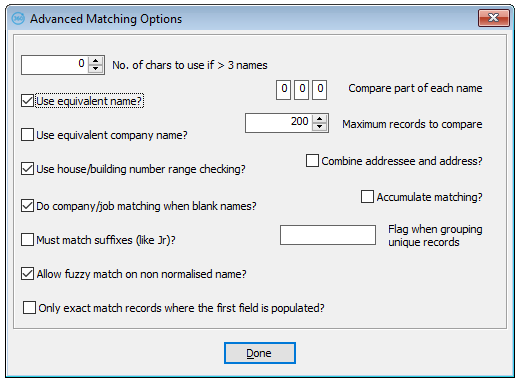
Use equivalent name
If you set the Use Equivalent Name parameter "on", mDesktop replaces the first name with its equivalent from the NAMES table, if there is an entry for the input forename. This enables, for example, "Tony Smith" and "Anthony Smith" to be picked up as a match. The initial of the original forename is stored in the FLAG field to enable, for example, "Tony Smith" and "T Smith" to still be matched. If time permits, you can Find Matches with this parameter set on, and then re-import the data with the parameter not set on and Find Matches again. The first run would pick up matches for, for example, Tony and Anthony, and the second would pick up any additional matches obscured by keying errors, for example, Tony and Tnoy.
Use equivalent company name
If this parameter is set "on", then the equivalent (according to the Names table) of words indicating a business name, such as "Motors" or "Services" are included in the name keys. This enables, for example, "Wood Green Cars" to match "Wood Green Motors" (because "Cars" has an equivalent of "Motors"), but not to match "Wood Green Carpets". The disadvantage is that words like "Ltd" and "Plc" are also included in the Match Keys so that business names written in different ways, such as "ABC Ltd" and "ABC Plc" may not match. As a rule of thumb, if you are doing business matching on a file that is very geographically concentrated, that is, contains records mostly from the same immediate area, then switch this parameter on, otherwise switch it off.
Use premise range checking
To use address coding (the facility to compare a file of addresses with a master file where the thoroughfare records on the master file are split into premise ranges), you must set Use Premise Range Checking ON in the Advanced Matching Parameters.
Do company/job matching when blank names
This parameters governs what mDesktop does when it is matching two personal names which are both empty. If the parameter is "on", mDesktop will compare the company names and job titles (where they exist), and record the match result. The name score result is then recorded as the minimum result of these two comparisons, as long as they both recorded at least a likely match result; otherwise the name result will be simply a 'both empty' result. For instance, if both the names in a potential pair are empty, the company names get a likely match and the job titles get a sure match, then the names will be scored as a likely match.
Must match suffixes
Set this parameter "on" if you want to suppress matches where the suffixes differ, such as "John Smith Sr" and "John Smith Jr", who are probably father and son. Note that, for this to work there must be a populated SUFFIX field in the file; mDesktop will populate this field on import, if it is empty and there is a suffix in the input name.
Compare Part of each Name
If a name isn't equal or approximately equal to its counterpart in the other record, mDesktop looks to see if the full name for the other record "Contains" it, in the sense that Christopher (or indeed Christine) "Contains" Chris. The three Compare Part Name fields specify to mDesktop three values of "n", a number of characters, to see if just the first n characters of each name (surname, first forename, second forename) are contained in the other full name. If you use Phonetic Name Matching, the comparisons mentioned here use the phonetic keys for each name, not the name itself.
To use all of a name or phonetic key in a comparison, set the appropriate one of these parameters to zero; this is the normal setting if you use Phonetic Name Matching. Otherwise specify the number of characters to use. Many diminutives of forenames differ in their endings from the curtailed full version of the name (for example Willy, Andy, Sue), so from this point of view, you should specify agreement of only two or three characters, and certainly no more than four. On the other hand, if you are using the forename look-up table and entering the new forenames that you find, you would normally set the Compare Part 1stname parameter to zero.
Maximum Records to Compare
The Maximum Records to Compare parameter is a whole number specifying the maximum number of records in a set with identical Match Keys, for which mDesktop will compare each record with every other record in the set. If mDesktop finds a key with more records than this value, it reports this information to the screen and to the PERFORM.TXT file in the REPORT sub-directory and skips to the next record with a higher key value.
For example: if you have Maximum Records to Compare set to 50, you are matching on NAME1+REST_PHONE and there are more than 50 records with a blank phone number and NAME1 equal to "dyvys" (e.g. Davies or Davis): mDesktop will compare the first such record with all the others, report that there are (say) 63 records with this key, then carry on with the next record with a higher key.
Combine Addressee and Address
If you set the Combine Addressee and Address parameter "on", mDesktop will combine the ADDRESSEE and ADDRESS1, ADDRESS2 etc. fields when comparing addresses during the matching process. If the Address fields in the Main File often contain an Addressee, it is worth selecting this option.
Accumulate Matching
When you set the Wait for User after Import option off (i.e. no pause) and you set the Accumulate Matching parameter "on", mDesktop will append the references of further matching pairs to the end of the MATCHES table, retaining the existing references; otherwise, it will overwrite these.
When you set the Wait for User after Import option "on" and you set the Accumulate Matching parameter "on", mDesktop will automatically append further matching pairs and won't ask the question "Is this a new matching analysis?"
Flag when grouping unique records
This parameter is used when flagging or grouping matches on a file with a MATCH_REF field. What happens is records that are involved in matches are marked with the unique reference of the 'master' record (the record which is kept) of the matching set; this reference is stored in the MATCH_REF field. This enables matching sets to be easily grouped together by indexing the file on the MATCH_REF field. If this parameter is an empty string, then the unique reference of every record that isn't involved in a matching set is put into its MATCH_REF field; this can make it difficult to distinguish records in matching sets from those that aren't. If this parameter is set to be a non-empty string, say "UNIQUE", then this string is put into the MATCH_REF field of unique records to make it easier to distinguish them from records in matching sets.
Modifying the Weights Used for Matching
Select the Weights option from the Jobs/Setup; Matching Setup menu if you wish to alter the values of the weights attached to the different fields in the matching process. You should not modify the matching weights unless you have read and understood the description in "Introduction to Matching".
A full description of Matching Weights and the Matching Matrices is given in the Online Help.
The Flag Matches option deletes the records with the lowest priorities from each set of matches. If priorities are equal, it keeps the latest record on the file from each set or the one with the lowest Unique Reference, depending on the value of the Flag Higher Reference? Basic Matching option.
A full description of Deletion Priorities is given in the Online Help.
- Field Name is the name of the field in the selected Main File - if any field is not present, the rule for that field is ignored.
- Comment is just for your guidance, to explain if necessary what the field name contains.
- Priority shows the value which is accumulated for each rule that applies to the record being evaluated. When deciding which record to delete, mDesktop accumulates priorities for each record and keeps the record with the highest total priority.
- Value specifies what Value the Field Name must be to obtain the Priority shown. The usual Value is "Empty" e.g. in the first rule above, if the surname (or first business name when matching business names) is empty, a Priority of -99 is given, which downgrades that record heavily. The other common Value is a constant e.g. if you specify rules as follows:
- There are some special Values which only apply to specific field names:
- "Default" applies only to the salutation field: the record will be downgraded in the example above if the salutation is the current default e.g. Dear Customer rather than e.g. Mr Smith.
- "First Name" and "Initial" apply to the first forename field, where it is a full name or an initial rather than empty. "First Name" can also apply to the 2nd significant word in a business name, when matching business names.
- "Derived" applies only to the Prefix field: if the Prefix is derived from the first forename e.g. Ms for Christine, the record will be downgraded compared with a supplied Prefix such as Mrs or Dr.
If you define a field called DEL_PRI (numeric), mDesktop will record the priority of each record that it examines for potential deletion, so you can check that your priorities are working as you expect.