
| Previous Article | matchIT Hub Index | Next Article |
Prerequisites
You will need an AWS account and the AWS CLI (Command Line Interface). For details of how to install and configure the CL see:
https://docs.aws.amazon.com/cli/latest/userguide/cli-chap-welcome.html
In order to create EMR cluster and submit Spark jobs, you will need to create and download a Key Pair, create default roles, and configure inbound rules.
Key pair
You will need a Key Pair when submitting jobs. Create and download a named Key Pair from the EC2 console. For more details see:
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ec2-key-pairs.html
Default roles
To create clusters in EMR we need a set of default roles. Use the following AWS CLI command to create a set of default rules:
$ aws emr create-default-roles
Inbound rules
In order to use the Spark UI, the CIDR range of IP addresses you are accessing from needs to be added to the master Security Group (SG). In the EC2 console: click on Security Groups in the left-hand menu and select the “ElasticMapReduce-master” security group. On the Inbound tab, click Edit to add a rule to allow your IP access.
Deploying matchIT Hub for Spark to AWS
Create an S3 bucket called matchithub-spark. Create a folder called “log”.
Copy your activation code to a file called activation.txt in the root folder of the bucket:
$ aws s3 cp activation.txt s3://matchithub-spark/
From your local matchIT Hub for Spark installation folder, copy the contents of the lib folder:
$ aws s3 cp matchithub-spark/lib s3://matchithub-spark/lib/ --recursive
Deploying the sample job
Copy the pre-built DedupeTextFile-jar-with-dependencies.jar, example1.txt, and sampleconfig.xml files from the DedupeTextFile sample app folder:
$ aws s3 cp matchithub-spark/samples/DedupeTextFile/DedupeTextFile-jar-with-dependencies.jar s3://matchithub-spark/samples/DedupeTextFile/$ aws s3 cp matchithub-spark/samples/DedupeTextFile/example1.txt s3://matchithub-spark/samples/DedupeTextFile/$ aws s3 cp matchithub-spark/samples/DedupeTextFile/sampleconfig.xml s3://matchithub-spark/samples/DedupeTextFile/
Running the sample job
In your matchIT Hub for Spark installation folder there is a sub-folder called ‘emr’. In there, you’ll find a script called matchithub-emr-runner.sh.
matchithub-emr-runner.sh
Uses the aws emr create-cluster command to spin up a cluster, submit and run a job (step), and auto-terminate the cluster. Edit this file change things like the instance type and availability zone.
Usage:
matchithub-emr-runner.sh <key_name> <job_name> <steps_file>
Where:
- <key_name> is the name of your Key Pairs file.
- <job_name> is an arbitrary name for the job.
- <steps_file> is a json file containing the steps to run (see below).
sample-job.json
Sample steps file. This contains the spark-submit command for running the DedupeTextFile application with the example1 data.
To submit the sample job, run:
matchithub-emr-runner.sh <key_name> sample sample-job.json
In the Amazon EMR console you should see a cluster called “sample” starting up. Once it completes, the output will be written to s3://matchithub-spark/samples/DedupeTextFile/outputPairs.
Cluster Tuning
Spark Application Execution
A Spark application consists of a single driver process, that runs on the master node, and a set of executor processes scattered across the worker nodes on the cluster.
Operations in Spark are lazy – that is, they are not executed until a result is required. Consider this simplified deduplication process:
// load main input
RDD
mainInput = sc.textFile(mainFileName_);
// Send data to Hub in Key Gen mode to appended key values to each record
RDD
keyed = mainInput.mapPartitions(new KeyGen());
// Output a {key, value} pair for each key
PairRDD<String, String>
keys = keyed.flatMapToPair(new KeyedToKeyValues());
// Group by key into clusters
PairRDD<String, Iterable> clusters = keys.groupByKey();
// Send pairs of records to Hub for comparison, output RDD is matching pairs
RDD pairs = clusters.mapPartitions(new PairMatching());
// output pairs
pairs.saveAsTextFile(outputPath_);
Although this looks like a normal program that you’d expect to be executed line by line as the developer coded it, Spark’s lazy execution means it doesn’t do anything it doesn’t need to do. The only line in the above program where a result is required (i.e. an action rather than a transformation) is the saveAsTextFile(). But in order to execute this it needs to create the pairs RDD, and to do that it needs to create the clusters RDD, and so on.
For each action Spark builds a graph of RDDs and, from this, forms an execution plan that is run as a job. The execution plan assembles the job’s transformations into stages. A stage is a collection of tasks that all execute the same transformations on different partitions of the data. Each stage contains a sequence of transformations that can be completed without shuffling the full data. A shuffle involves re-partitioning the data and moving data between nodes – this is expensive as it involves writing to disk and transmitting data across the network. In the above program the only transformation that requires a shuffle is the groupByKey().
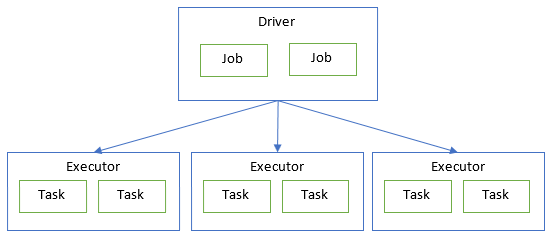
Each worker node in the cluster can run multiple executors. Each executor is a Java JVM and can run multiple tasks at the same time.
AWS Cluster
In AWS, a cluster is made up of EC2 (Elastic Compute Cloud) virtual machines. Instance types are divided into General-purpose (A, T, M), Compute-optimised (C), Memory-optimised (R, X), Accelerated (P, G, F), Storage-optimised (H, I, D). Within each category, different models have specs and costs e.g.:
| Model | vCPU | Mem (GiB) | $ per Hour |
|---|---|---|---|
| m5.large | 2 | 8 | 0.107 |
| m5.xlarge | 4 | 16 | 0.214 |
| m5.2xlarge | 8 | 32 | 0.428 |
| m5.4xlarge | 16 | 64 | 0.856 |
| m5.12xlarge | 48 | 192 | 2.568 |
| m5.24xlarge | 96 | 384 | 5.136 |
Typically, each vCPU (or core) can run 2 threads at once.
Cluster Configuration
A cluster is configured via the following settings.
| executor-cores | The number of cores assigned to each executor. |
|---|---|
| num-executors | Total number of executors in the cluster. |
| executor-memory | The amount of Heap memory assigned to each executor JVM. |
| memoryOverhead | The amount of off-Heap memory in MiB assigned to each executor JVM. |
| task-cpus | The number of cores available to each task (default 1). |
Say, we have a 4 node cluster of m5.4xlarge.
| Nodes | 4 |
|---|---|
| Cores-per-node | 16 |
| RAM-per-node | 64 |
Strategies for configuring a cluster include: tiny executors, fat executors, balanced executors (See: https://spoddutur.github.io/spark-notes/distribution_of_executors_cores_and_memory_for_spark_application.html).
Tiny executors
Tiny executors are assigned 1 cpu each. The number of executors-per-node is then the same as cores-per-node, and the total number of executors is nodes * executors-per-node. Executor memory is the ram-per-node divided by executors-per-node, so:
--executor-cores=1 --num-executors=64 --executor-memory=4g
Fat executors
Fat executors are assigned all the cpus on a node. The number of executors then, is the number of nodes, and executor memory is all the RAM available on each node, so:
--executor-cores=16 --num-executors=4 --executor-memory=64g
Balances executors
Balanced executors are assigned 5 cpus (for good HDFS throughput apparently). This gives us room for 3 executors per node with 1 core left over for Hadoop/Yarn daemons. Available memory per executor is 64/3=21.3, allowing 10% for off-heap memory gives:
--executor-cores=5 --num-executors=12 --executor-memory=19.8g --memoryoverhead=1525
Overhead memory
The default memory overhead is 7% of the exec-memory. The exec-memory is the space allowed for the Heap in the Java JVM. This would be fine if all the work was being done in Java, but Hub is running outside of Java so we need to increase the overhead. A memory overhead of around 20% seems to work well.
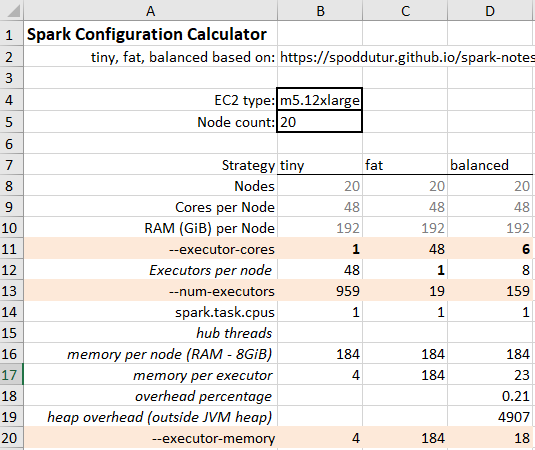
Spark Configuration Calculator
We can provide a spreadsheet, “Spark config calculator.xlsx” based on the above.
| Previous Article | matchIT Hub Index | Next Article |