
| Previous Article | matchIT Hub Index | Next Article |
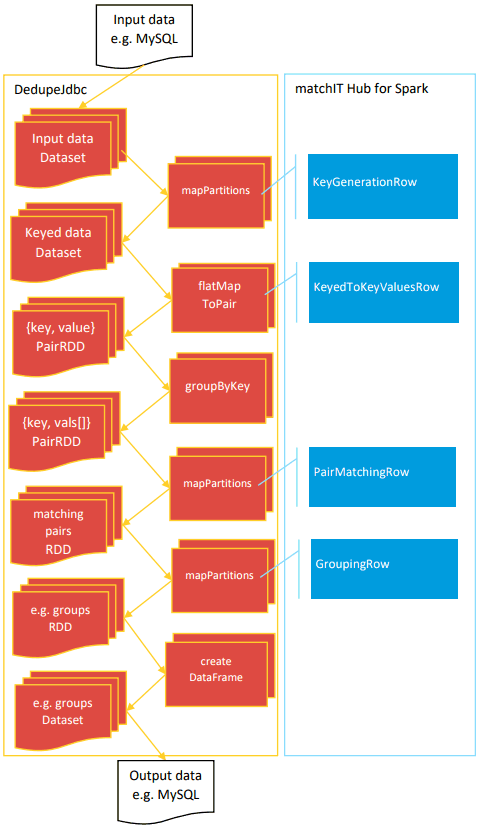
The DedupeJdbc application demonstrates using the matchIT Hub for Spark ‘Row’ classes to work with SQL tables, Rows, and Spark Dataset & RDDs.
Configuration
The command line argument to DedupeJdbc is the name of a configuration file. This is an xml file in the following format:
<?xml version="1.0" encoding="utf-8" ?>
<config>
<dedupeJdbc>
<!-- Define one input for single table Matching -->
<input>
<connectionString>jdbc:sqlserver://localhost;DatabaseName=test;IntegratedSecurity=true;</connectionString>
<table>dbo.uk1m</table>
<partitionColumn>ID</partitionColumn>
<lowerBound>1</lowerBound>
<upperBound>1000000</upperBound>
<numPartitions>3</numPartitions>
</input>
<!-- Define two inputs for Overlap Matching
<input>
</input> -->
<!-- Output database and table name. -->
<output>
<connectionString>jdbc:sqlserver://localhost;DatabaseName=test;IntegratedSecurity=true;</connectionString>
<table>dbo.matchingPairsSpark</table>
</output>
<delimiter>\t</delimiter>
<licenceFile>./activation.txt</licenceFile>
<logLevel>error</logLevel>
<groupingAlgorithm>hub</groupingAlgorithm>
<idField>0</idField>
<maxIterations>4</maxIterations>
</dedupeJdbc>
<hub>
<data>
<input table="0" columns="|UniqueRef|FullName|Company|Address1|Address2|City|State|Zip" />
<options>...</options>
</data>
<matching>
<outputs>...</outputs>
</matching>
<threads>0</threads>
<advanced>
<nationality>USA</nationality>
</advanced>
</hub>
</config>
The <dedupeJdbc> section is specific to this application.
| input | Details of an input database table. |
| connectionString | Jdbc connection string. |
| table | The name of a database table. |
| partitionColumn, lowerBound, upperBound, numPartitions | partitionColumn, lowerBound, upperBound, numPartitions must all be specified to load the data into multiple partitions in parallel. Refer to the Spark documentation for details. |
| output | Details of an output database table. |
| delimiter | The delimiter used when converting records to delimited string in order to pass to the underlying matching engine. |
| licenceFile | A file containing the product activation code. |
See DedupeConfiguration for a description of the configuration options: licenceFile, logLevel, groupingAlgorithm, idField, and maxIterations.
The <hub> section configures the underlying matching engine. Refer to the matchIT Hub documentation for details. The <hub> section must contain the following sub-sections: data, matching, threads, advanced.
Running the sample
The DedupeJdbc sample can’t be run out-the-box like the DedupeTextFile sample because it requires a SQL database and the relevant Jdbc drivers. Nevertheless, a sampleconfig.xml and run.sh are provided to demonstrate how to set this up to run.
| Previous Article | matchIT Hub Index | Next Article |